Recomendación de items frecuentes en supermercados usando Apriori¶
30 min | Ultima modificación: Junio 22, 2019
En este ejemplo se desarrolla un sistema de reglas de asociación usando el algoritmo Apriori para realizar recomendaciones a clientes a partir de su compra actual.
Descripción del problema¶
Una cadena de supermercados desea construir un sistema de recomendación para su página web que sugiera a un comprador otros productos que podrían interesarle dependiendo de la búsqueda o la selección de productos que haya realizado en el momento de realizar la selección.
Se tiene una base de datos de 9835 transacciones recolectadas de forma continua durante 12 días para un supermercado relativamente pequeño. Para hacer este problema manejable no se tuvieron en cuenta las posibles marcas de un mismo producto ni los distintos tipos de presentaciones. De esta forma, se tienen registros de 169 tipos de productos como chicken, frozen meals, margarine, etc. El objetivo en términos de los datos consiste en determinar los grupos de productos que se compran
frecuentemente juntos con el fin de que cuando un cliente seleccione uno o más items de un determinado grupo, los restantes elementos le sean sugeridos automáticamente por el sistema.
Preparación¶
[1]:
##
## Preparación. Se utiliza el paquete rpy2
## para ejecutar código R dentro de Python.
##
%load_ext rpy2.ipython
[2]:
%%sh
PACK=arules
if /usr/bin/test ! -d /usr/local/lib/R/site-library/$PACK;
then
sudo Rscript -e 'install.packages("'$PACK'")'
fi
[3]:
%%R
##
## Carga de los datos
##
library(arules)
R[write to console]: Loading required package: Matrix
R[write to console]:
Attaching package: ‘arules’
R[write to console]: The following objects are masked from ‘package:base’:
abbreviate, write
Lectura de datos¶
[4]:
%%R
groceries <- read.transactions("https://raw.githubusercontent.com/jdvelasq/datalabs/master/datasets/groceries.csv", sep = ",")
El archivo anterior contiene una transacción por fila, y los items comprados por transacción aparecen separados por coma:
citrus fruit,semi-finished bread,margarine,ready soups
tropical fruit,yogurt,coffee
whole milk
pip fruit,yogurt,cream cheese ,meat spreads
other vegetables,whole milk,condensed milk,long life bakery product
whole milk,butter,yogurt,rice,abrasive cleaner
rolls/buns
other vegetables,UHT-milk,rolls/buns,bottled beer,liquor (appetizer)
pot plants
whole milk,cereals
Una de las dificultades para manejar esta información es que cada fila puede contener un número diferente de elementos por lo que no es posible usar directamente un data.frame y se utiliza una matriz esparcida.
Análisis exploratorio¶
[5]:
%%R
##
## Se obtiene la información más relevante de los datos. Los
## resultados indican lo siguiente:
##
## * Hay 9.835 transacciones con 169 items (ok!)
##
## * Los productos más vendidos son:
##
## producto transacciones en
## las que aparece
## ------------------------------------
## whole milk 2.513
## other vegetables 1.903
## ...
##
## * Hay 2.159 transacciones con 1 ítem, 1.643 con 2 ítems, ...,
## hay una sola transacción con 32 ítems
##
##
summary(groceries)
transactions as itemMatrix in sparse format with
9835 rows (elements/itemsets/transactions) and
169 columns (items) and a density of 0.02609146
most frequent items:
whole milk other vegetables rolls/buns soda
2513 1903 1809 1715
yogurt (Other)
1372 34055
element (itemset/transaction) length distribution:
sizes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
2159 1643 1299 1005 855 645 545 438 350 246 182 117 78 77 55 46
17 18 19 20 21 22 23 24 26 27 28 29 32
29 14 14 9 11 4 6 1 1 1 1 3 1
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.000 2.000 3.000 4.409 6.000 32.000
includes extended item information - examples:
labels
1 abrasive cleaner
2 artif. sweetener
3 baby cosmetics
La segunda parte de la tabla anterior indica la cantidad de transacciones que tienen un solo item, luego dos y así sucesivamente.
element (itemset/transaction) length distribution:
sizes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
2159 1643 1299 1005 855 645 545 438 350 246 182 117 78 77 55 46
17 18 19 20 21 22 23 24 26 27 28 29 32
29 14 14 9 11 4 6 1 1 1 1 3 1
Esta misma tabla indica que hay una transacción en que se compraron 32 items.
[6]:
%%R
##
## Se visualizan los items comprados en las primeras
## cinco transacciones (filas del archivo)
##
inspect(groceries[1:5])
items
[1] {citrus fruit,
margarine,
ready soups,
semi-finished bread}
[2] {coffee,
tropical fruit,
yogurt}
[3] {whole milk}
[4] {cream cheese,
meat spreads,
pip fruit,
yogurt}
[5] {condensed milk,
long life bakery product,
other vegetables,
whole milk}
[7]:
%%R
##
## Se imprime la frequencia con que se compraron los primeros
## tres items (note que esta organizado alfabeticamente)
##
itemFrequency(groceries[, 1:3])
abrasive cleaner artif. sweetener baby cosmetics
0.0035587189 0.0032536858 0.0006100661
[8]:
%%R
##
## Se grafica un histograma que muestra la frecuencia
## con que se compraron ciertos items. El parámetro
## `support` corresponde a la frecuencia mínima que
## deben tener un item para que sea incluído en la gráfica.
## En este caso un item debe aparecer en 0.1 * 9385 = 938.5
## transacciones para ser tenido en cuenta.
##
itemFrequencyPlot(groceries, support = 0.1)
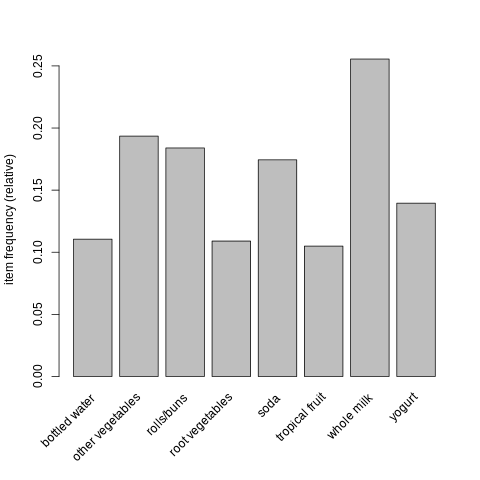
[9]:
%%R
##
## Se obtiene la misma gráfica anterior pero para los
## 20 items más comprados.
##
itemFrequencyPlot(groceries, topN = 20)
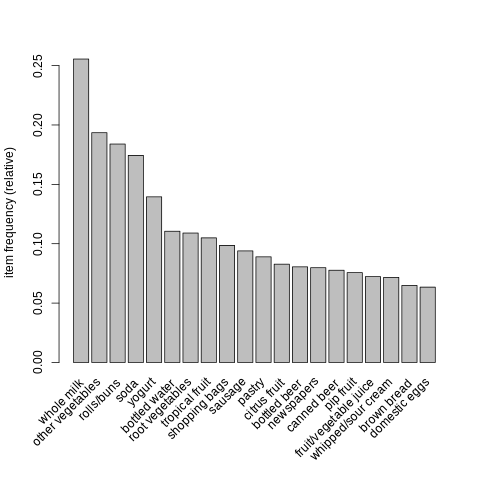
[10]:
%%R
##
## Se puede visualizar la matriz de items
## y transacciones para una muestra aleatoria.
## Una linea vertical muestra items que podrían ser
## comprados en cada transacción
##
image(sample(groceries, 100))
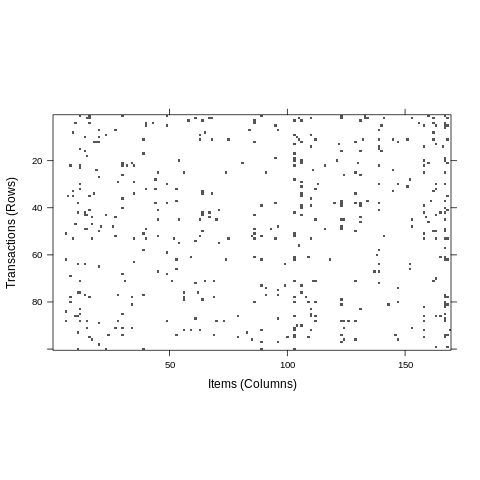
Construcción del modelo¶
[11]:
%%R
##
## La corrida con los parámetros por defecto de la
## función no generan reglas para los datos suministrados.
## El valor por defecto de support es 0.1, es decir,
## un item debe aparecer en un mínimo de 938.5 transacciones
## para ser considerado
##
apriori(groceries)
Apriori
Parameter specification:
confidence minval smax arem aval originalSupport maxtime support minlen
0.8 0.1 1 none FALSE TRUE 5 0.1 1
maxlen target ext
10 rules FALSE
Algorithmic control:
filter tree heap memopt load sort verbose
0.1 TRUE TRUE FALSE TRUE 2 TRUE
Absolute minimum support count: 983
set item appearances ...[0 item(s)] done [0.00s].
set transactions ...[169 item(s), 9835 transaction(s)] done [0.01s].
sorting and recoding items ... [8 item(s)] done [0.00s].
creating transaction tree ... done [0.00s].
checking subsets of size 1 2 done [0.00s].
writing ... [0 rule(s)] done [0.00s].
creating S4 object ... done [0.00s].
set of 0 rules
[12]:
%%R
##
## El parámetro confianza representa el porcentaje mínimo
## de veces que una regla debe ser correcta para que
## sea considerada; esto permite eliminar reglas sin
## sentido. El parámetro minlen indica que las reglas
## deben contener al menos 2 items.
##
groceryrules <- apriori(groceries,
parameter = list(support = 0.006,
confidence = 0.25,
minlen = 2))
Apriori
Parameter specification:
confidence minval smax arem aval originalSupport maxtime support minlen
0.25 0.1 1 none FALSE TRUE 5 0.006 2
maxlen target ext
10 rules FALSE
Algorithmic control:
filter tree heap memopt load sort verbose
0.1 TRUE TRUE FALSE TRUE 2 TRUE
Absolute minimum support count: 59
set item appearances ...[0 item(s)] done [0.00s].
set transactions ...[169 item(s), 9835 transaction(s)] done [0.01s].
sorting and recoding items ... [109 item(s)] done [0.00s].
creating transaction tree ... done [0.01s].
checking subsets of size 1 2 3 4 done [0.01s].
writing ... [463 rule(s)] done [0.00s].
creating S4 object ... done [0.00s].
[13]:
%%R
##
## Número de reglas generadas
##
groceryrules
set of 463 rules
Evaluación del modelo¶
[14]:
%%R
##
## Se obtiene la cantidad de reglas, la cantidad
## de elementos por regla, y el resumen de las
## métricas de calidad
##
summary(groceryrules)
set of 463 rules
rule length distribution (lhs + rhs):sizes
2 3 4
150 297 16
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.000 2.000 3.000 2.711 3.000 4.000
summary of quality measures:
support confidence lift count
Min. :0.006101 Min. :0.2500 Min. :0.9932 Min. : 60.0
1st Qu.:0.007117 1st Qu.:0.2971 1st Qu.:1.6229 1st Qu.: 70.0
Median :0.008744 Median :0.3554 Median :1.9332 Median : 86.0
Mean :0.011539 Mean :0.3786 Mean :2.0351 Mean :113.5
3rd Qu.:0.012303 3rd Qu.:0.4495 3rd Qu.:2.3565 3rd Qu.:121.0
Max. :0.074835 Max. :0.6600 Max. :3.9565 Max. :736.0
mining info:
data ntransactions support confidence
groceries 9835 0.006 0.25
[15]:
%%R
##
## Se visualizan las primeras 10 reglas.
##
inspect(groceryrules[1:10])
lhs rhs support confidence
[1] {pot plants} => {whole milk} 0.006914082 0.4000000
[2] {pasta} => {whole milk} 0.006100661 0.4054054
[3] {herbs} => {root vegetables} 0.007015760 0.4312500
[4] {herbs} => {other vegetables} 0.007727504 0.4750000
[5] {herbs} => {whole milk} 0.007727504 0.4750000
[6] {processed cheese} => {whole milk} 0.007015760 0.4233129
[7] {semi-finished bread} => {whole milk} 0.007117438 0.4022989
[8] {beverages} => {whole milk} 0.006812405 0.2617188
[9] {detergent} => {other vegetables} 0.006405694 0.3333333
[10] {detergent} => {whole milk} 0.008947636 0.4656085
lift count
[1] 1.565460 68
[2] 1.586614 60
[3] 3.956477 69
[4] 2.454874 76
[5] 1.858983 76
[6] 1.656698 69
[7] 1.574457 70
[8] 1.024275 67
[9] 1.722719 63
[10] 1.822228 88
[16]:
%%R
##
## Se puede inspeccionar un conjunto de reglas en particular
##
inspect(sort(groceryrules, by = "lift")[1:5])
lhs rhs support confidence lift count
[1] {herbs} => {root vegetables} 0.007015760 0.4312500 3.956477 69
[2] {berries} => {whipped/sour cream} 0.009049314 0.2721713 3.796886 89
[3] {other vegetables,
tropical fruit,
whole milk} => {root vegetables} 0.007015760 0.4107143 3.768074 69
[4] {beef,
other vegetables} => {root vegetables} 0.007930859 0.4020619 3.688692 78
[5] {other vegetables,
tropical fruit} => {pip fruit} 0.009456024 0.2634561 3.482649 93
[17]:
%%R
##
## Se puede obtener un subconjunto de las reglas que
## cumplen una condición particular
##
berryrules <- subset(groceryrules, items %in% "berries")
inspect(berryrules)
lhs rhs support confidence lift count
[1] {berries} => {whipped/sour cream} 0.009049314 0.2721713 3.796886 89
[2] {berries} => {yogurt} 0.010574479 0.3180428 2.279848 104
[3] {berries} => {other vegetables} 0.010269446 0.3088685 1.596280 101
[4] {berries} => {whole milk} 0.011794611 0.3547401 1.388328 116
[18]:
%%R
##
## Se pueden almacenar las reglas en el disco
##
write(groceryrules,
file = "groceryrules.csv",
sep = ",",
quote = TRUE,
row.names = FALSE)
[19]:
!head groceryrules.csv
"rules","support","confidence","lift","count"
"{pot plants} => {whole milk}",0.00691408235892222,0.4,1.56545961002786,68
"{pasta} => {whole milk}",0.00610066090493137,0.405405405405405,1.58661446962283,60
"{herbs} => {root vegetables}",0.00701576004067107,0.43125,3.95647737873134,69
"{herbs} => {other vegetables}",0.00772750381291307,0.475,2.45487388334209,76
"{herbs} => {whole milk}",0.00772750381291307,0.475,1.85898328690808,76
"{processed cheese} => {whole milk}",0.00701576004067107,0.423312883435583,1.65669805355709,69
"{semi-finished bread} => {whole milk}",0.00711743772241993,0.402298850574713,1.57445650433836,70
"{beverages} => {whole milk}",0.00681240467717336,0.26171875,1.02427533077994,67
"{detergent} => {other vegetables}",0.00640569395017794,0.333333333333333,1.72271851462603,63
[20]:
%%R
##
## Se pueden convertir a un data.frame
##
groceryrules_df <- as(groceryrules, "data.frame")
str(groceryrules_df)
'data.frame': 463 obs. of 5 variables:
$ rules : Factor w/ 463 levels "{baking powder} => {other vegetables}",..: 340 302 207 206 208 341 402 21 139 140 ...
$ support : num 0.00691 0.0061 0.00702 0.00773 0.00773 ...
$ confidence: num 0.4 0.405 0.431 0.475 0.475 ...
$ lift : num 1.57 1.59 3.96 2.45 1.86 ...
$ count : num 68 60 69 76 76 69 70 67 63 88 ...
Ejercicio.— ¿Cómo se usan las reglas obtenidas cuándo se sabe que un cliente ha seleccionado ciertos productos?
[21]:
!rm *.csv