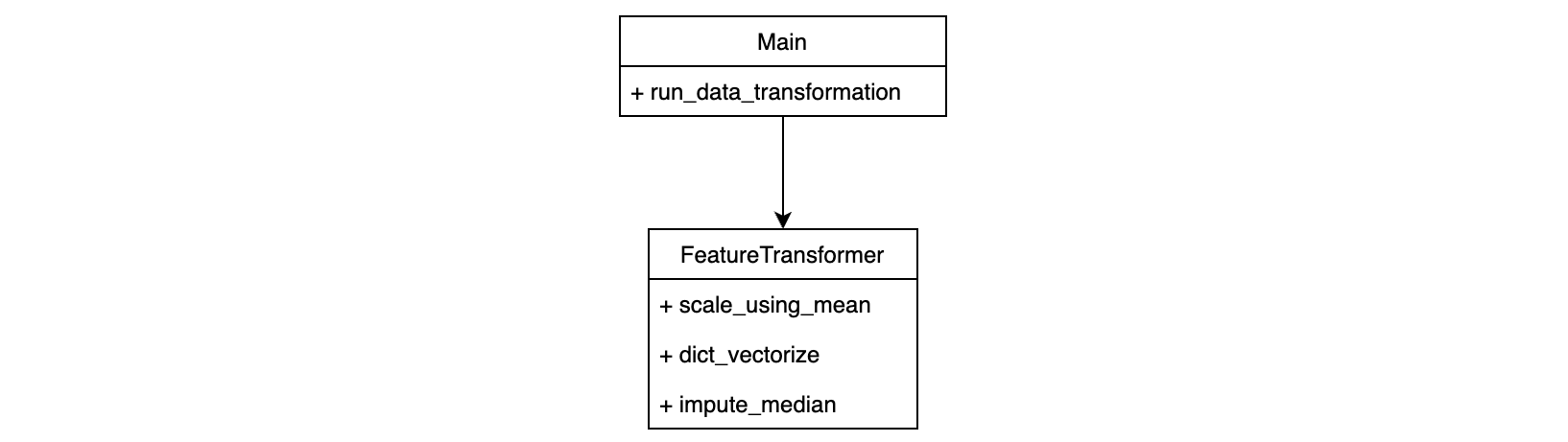
Principio de abierto-cerrado#
Última modificación: Mayo 14, 2022
El código cambiará en el futuro
[ ]:
#
# Analice el siguiente código: ¿puede encontrar defectos de diseño?
#
from typing import List
import pandas as pd
from pandas import DataFrame
class FeatureTransformer:
def __init__(self, name: str):
self.name = name
def scale_using_mean(self, data: DataFrame):
print(f"Running Mean Scaler using: {data.shape}")
return "scaled data"
def dict_vectorize(self, data: DataFrame):
print(f"Running Dict Vectorizer using: {data.shape}")
return "vectorized data"
def run_data_transformations(
train_data: DataFrame,
feature_transformers: List,
):
res = []
for transformer in feature_transformers:
if transformer.name == "mean_scaler":
res.append(transformer.scale_using_mean(train_data))
elif transfomer.name == "dict_vectorizer":
res.append(transformer.dict_vectorize(train_data))
else:
pass
return res
transformers = [
FeatureTransformer("mean_scaler"),
FeatureTransformer("dict_vectorizer"),
]
train_data = pd.DataFrame(
{
"user_id": list("1234"),
"age": [20, 21, 22, 23],
"income_id": [1, 1, 3, 4],
}
)
res = run_data_transformations(train_data, transformers)
[ ]:
#
# Rta/
#
from typing import List
import pandas as pd
from pandas import DataFrame
class FeatureTransformer:
#
# Viola el principio de responsabilidad única
#
def __init__(self, name: str):
self.name = name
def scale_using_mean(self, data: DataFrame):
print(f"Running Mean Scaler using: {data.shape}")
return "scaled data"
def dict_vectorize(self, data: DataFrame):
print(f"Running Dict Vectorizer using: {data.shape}")
return "vectorized data"
def run_data_transformations(
train_data: DataFrame,
feature_transformers: List,
):
#
# Viola el principio de open-closed: la función no está cerrada ante la
# creación de nuevos transformadores. ¿Qué pasa si se adiciona
# `median_imputer` a FeatureTransformer?
#
res = []
for transformer in feature_transformers:
if transformer.name == "mean_scaler":
res.append(transformer.scale_using_mean(train_data))
elif transfomer.name == "dict_vectorizer":
res.append(transformer.dict_vectorize(train_data))
else:
pass
return res
transformers = [
FeatureTransformer("mean_scaler"),
FeatureTransformer("dict_vectorizer"),
]
train_data = pd.DataFrame(
{
"user_id": list("1234"),
"age": [20, 21, 22, 23],
"income_id": [1, 1, 3, 4],
}
)
res = run_data_transformations(train_data, transformers)
[ ]:
#
# Adición de `median_imputer`
#
from typing import List
import pandas as pd
from pandas import DataFrame
class FeatureTransformer:
def __init__(self, name: str):
self.name = name
def scale_using_mean(self, data: DataFrame):
print(f"Running Mean Scaler using: {data.shape}")
return "scaled data"
def dict_vectorize(self, data: DataFrame):
print(f"Running Dict Vectorizer using: {data.shape}")
return "vectorized data"
# ---->>>
def impute_median(self, data: DataFrame):
print(f"Running Median Imputer using {data.shape}")
return "median imputed data"
# <<<----
def run_data_transformations(
train_data: DataFrame,
feature_transformers: List,
):
res = []
for transformer in feature_transformers:
if transformer.name == "mean_scaler":
res.append(transformer.scale_using_mean(train_data))
elif transfomer.name == "dict_vectorizer":
res.append(transformer.dict_vectorize(train_data))
# ---->>>
elif transformer.name == "median_imputer":
res.append(transformer.impute_median(train_data))
# <<<----
else:
pass
return res
transformers = [
FeatureTransformer("mean_scaler"),
FeatureTransformer("dict_vectorizer"),
# ---->>>>
FeatureTransformer("mean_imputer"),
# <<<-----
]
train_data = pd.DataFrame(
{
"user_id": list("1234"),
"age": [20, 21, 22, 23],
"income_id": [1, 1, 3, 4],
}
)
res = run_data_transformations(train_data, transformers)
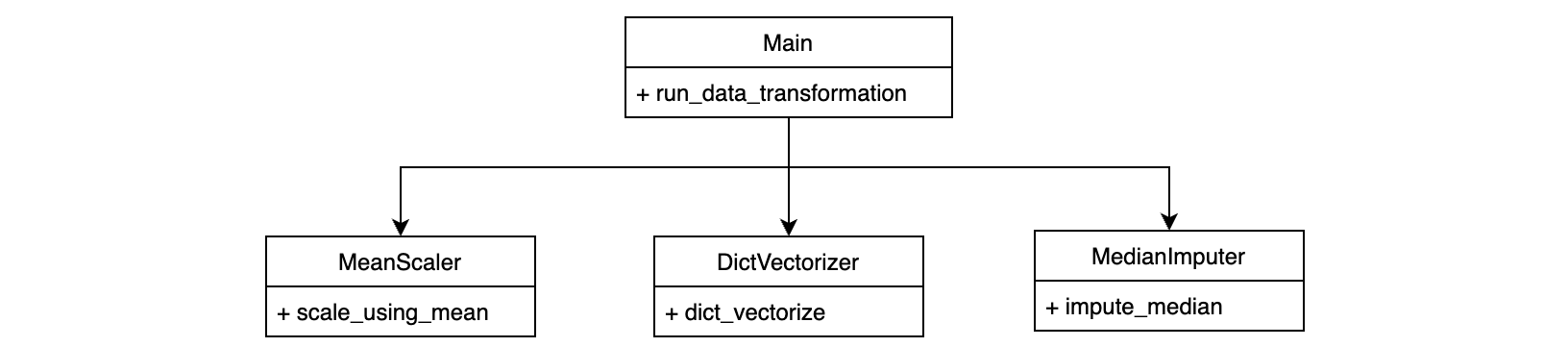
Mejora del código. Solo se mejora la parte del transformador#
[ ]:
from typing import List
import pandas as pd
from pandas import DataFrame
class MeanScaler:
def __init__(self, name: str):
self.name = name
def scale_using_mean(self, data: DataFrame):
print(f"Running Mean Scaler using: {data.shape}")
return "scaled data"
class DictVectorizer:
def __init__(self, name: str):
self.name = name
def dict_vectorize(self, data: DataFrame):
print(f"Running Dict Vectorizer using: {data.shape}")
return "vectorized data"
class MedianImputer:
def __init__(self, name: str):
self.name = name
def impute_median(self, data: DataFrame):
print(f"Running Median Imputer using {data.shape}")
return "median imputed data"
def run_data_transformations(
train_data: DataFrame,
feature_transformers: List,
):
res = []
for transformer in feature_transformers:
if transformer.name == "mean_scaler":
res.append(transformer.scale_using_mean(train_data))
elif transfomer.name == "dict_vectorizer":
res.append(transformer.dict_vectorize(train_data))
elif transformer.name == "median_imputer":
res.append(transformer.impute_median(train_data))
else:
pass
return res
transformers = [
MeanScaler("mean_scaler"),
DictVectorizer("dict_vectorizer"),
MedianImputer("median_imputer"),
]
train_data = pd.DataFrame(
{
"user_id": list("1234"),
"age": [20, 21, 22, 23],
"income_id": [1, 1, 3, 4],
}
)
res = run_data_transformations(train_data, transformers)
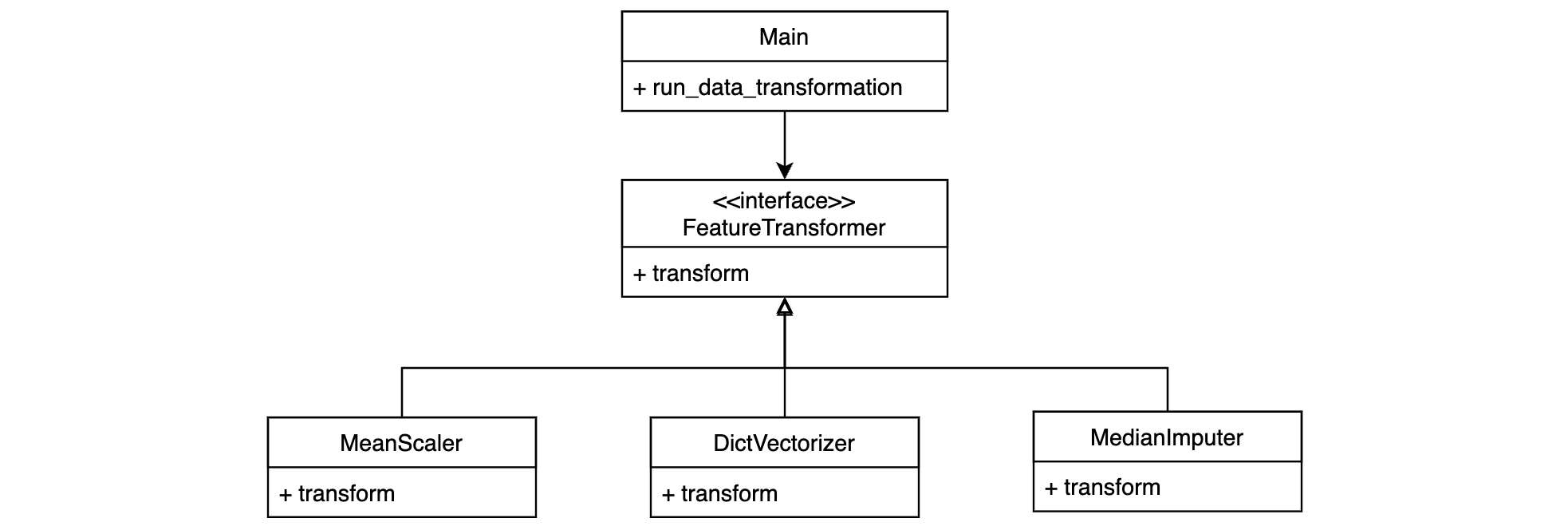
Abstracción#
[ ]:
from abc import ABC, abstractmethod
from typing import List
import pandas as pd
from pandas import DataFrame
class FeatureTransformer(ABC):
@abstractmethod
def transform(self, data: DataFrame):
pass
class MeanScaler(FeatureTransformer):
def transform(self, data: DataFrame):
print(f"Running Mean Scaler using: {data.shape}")
return "scaled data"
class DictVectorizer(FeatureTransformer):
def transform(self, data: DataFrame):
print(f"Running Dict Vectorizer using: {data.shape}")
return "vectorized data"
class MedianImputer(FeatureTransformer):
def transform(self, data: DataFrame):
print(f"Running Median Imputer using {data.shape}")
return "median imputed data"
def run_data_transformations(
train_data: DataFrame,
feature_transformers: List,
):
res = []
for transformer in feature_transformers:
res.append(transformer.transform(train_data))
return res
transformers = [
MeanScaler(),
DictVectorizer(),
MedianImputer(),
]
train_data = pd.DataFrame(
{
"user_id": list("1234"),
"age": [20, 21, 22, 23],
"income_id": [1, 1, 3, 4],
}
)
res = run_data_transformations(train_data, transformers)