Conteo de palabras en PySpark#
Última modificacion: Junio 22, 2019
En este tutorial se introducen los principales conceptos del algoritmo MapReduce en que se basa el modelo de Big Data. Como ejemplo se presenta, el conteo de palabras de un grupo de archivos.
Al finalizar este tutorial, usted estará en capacidad de:
Explicar los fundamentos del algoritmo MapReduce.
Mover un conjunto de archivos entre el sistema local y el sistema HDFS.
Aplicar MapReduce al conteo de frecuencia de elementos.
Definición del problema#
Se desea contar la frecuencia de las palabras que aparecen en varios archivos de textos. Para simplificar el problema, pruebe el algoritmo con los archivos generados en las siguientes celdas.
[1]:
#
# Se crea el directorio de entrada
#
!rm -rf /tmp/wordcount
!mkdir -p /tmp/wordcount/input
%cd /tmp/wordcount
!ls
/tmp/wordcount
input
[2]:
%%writefile input/text0.txt
Analytics is the discovery, interpretation, and communication of meaningful patterns
in data. Especially valuable in areas rich with recorded information, analytics relies
on the simultaneous application of statistics, computer programming and operations research
to quantify performance.
Organizations may apply analytics to business data to describe, predict, and improve business
performance. Specifically, areas within analytics include predictive analytics, prescriptive
analytics, enterprise decision management, descriptive analytics, cognitive analytics, Big
Data Analytics, retail analytics, store assortment and stock-keeping unit optimization,
marketing optimization and marketing mix modeling, web analytics, call analytics, speech
analytics, sales force sizing and optimization, price and promotion modeling, predictive
science, credit risk analysis, and fraud analytics. Since analytics can require extensive
computation (see big data), the algorithms and software used for analytics harness the most
current methods in computer science, statistics, and mathematics.
Writing input/text0.txt
[3]:
%%writefile input/text1.txt
The field of data analysis. Analytics often involves studying past historical data to
research potential trends, to analyze the effects of certain decisions or events, or to
evaluate the performance of a given tool or scenario. The goal of analytics is to improve
the business by gaining knowledge which can be used to make improvements or changes.
Writing input/text1.txt
[4]:
%%writefile input/text2.txt
Data analytics (DA) is the process of examining data sets in order to draw conclusions
about the information they contain, increasingly with the aid of specialized systems
and software. Data analytics technologies and techniques are widely used in commercial
industries to enable organizations to make more-informed business decisions and by
scientists and researchers to verify or disprove scientific models, theories and
hypotheses.
Writing input/text2.txt
Algoritmo MapReduce#
MapReduce es el término utilizado para describir un modelo de programación en paralelo que permite el procesamiento de grandes volúmenes de datos o Big Data que resultan difíciles de procesar en las aplicaciones tradicionales de procesamiento de datos. En el concepto de Big Data convergen las técnicas de almacenamiento distribuido de datos con la computación de alto desempeño mediante clusters.
Para ejemplificar el proceso, a continuación se presenta el ejemplo del conteo de la frecuencia de las letras que aparecen en el texto:
A A C
C B D
A C D
En la figura de abajo aparece, el esquema de operación de MapReduce.
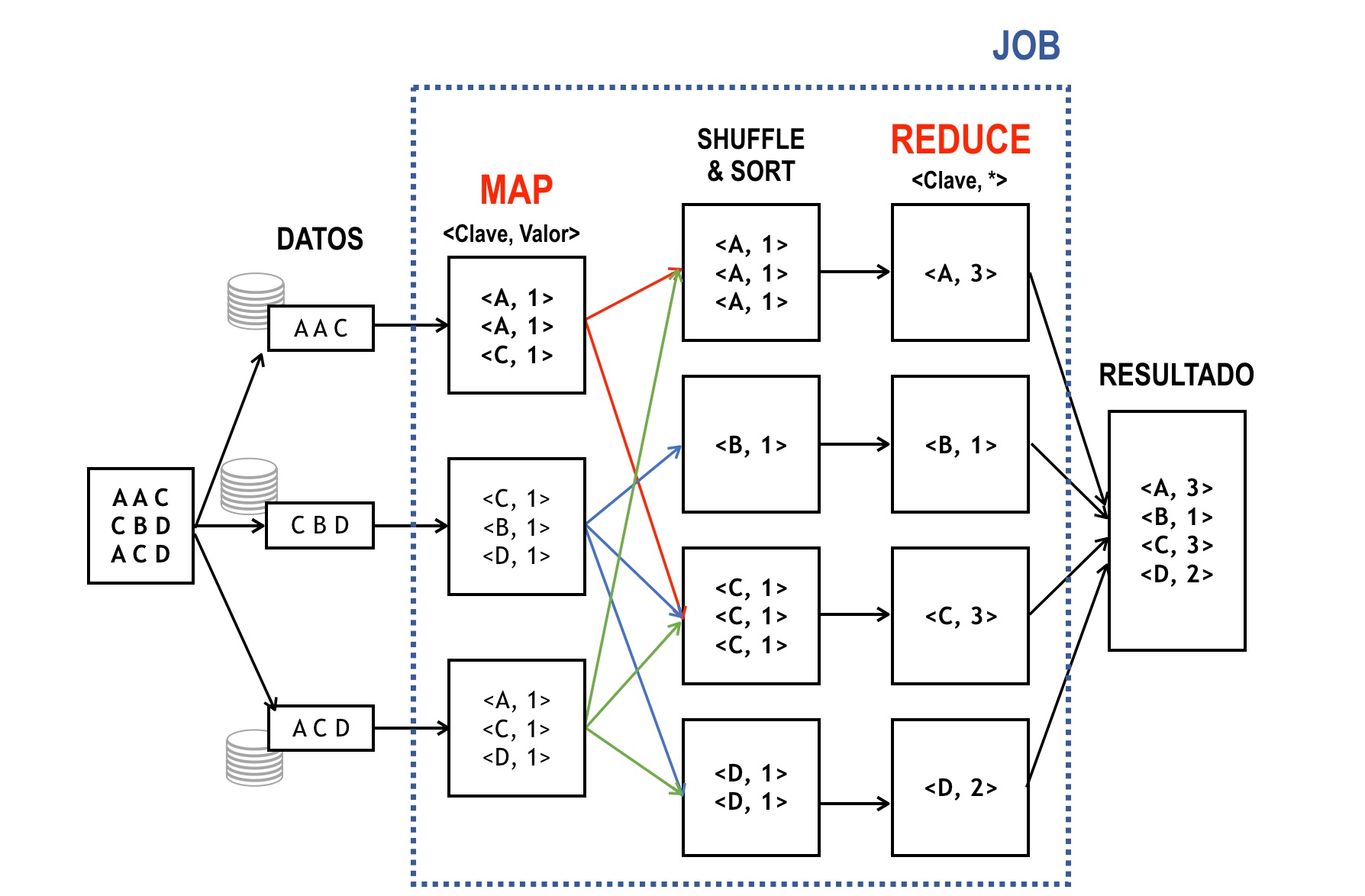
El proceso está conformado por los siguientes pasos:
Paso 1.– Cada línea del archivo es enviada a un proceso diferente (que podría ser un nodo diferente de un clúster); esto permite la operación en paralelo sobre conjuntos muy grandes de datos.
Paso 2.– MAP: El mapeo consiste en convertir la información a parejas <clave, valor>. La definición de que se toma como clave y que se toma como valor depende de cada problema específico. En el ejemplo presentado, para realizar el conteo de letras, la clave corresponde a la letra y el valor al número 1 (conteo). La función que realiza este proceso se conoce como mapper.
Paso 3.– SORT: El sistema ordena las parejas <clave, valor>, tal que todas las parejas que tengan la misma clave queden juntas.
Paso 4.–REDUCE: Consiste en reducir todas las parejas que tienen la misma clave a una sola; para ello, se debe definir como se computará (reducirá) el valor final. Para este ejemplo, la reducción consiste en sumar todos los valores que tengan la misma clave. La función que realiza este proceso se conoce como reducer.
Paso 5.– El sistema entrega el resultado consolidado.
El proceso de mapear y reducir se conoce como un trabajo (Job). Un cómputo complejo puede requerir muchos jobs, los cuales pueden ser ordenados en procesos, de acuerdo con los requerimientos. Varios ejemplos de encadenamientos de jobs pueden verse en la siguiente figura, donde la M representa el mapper y R el reducer. SS es shuffle & sort que es donde se ordenan las parejas <clave, valor> por claves.
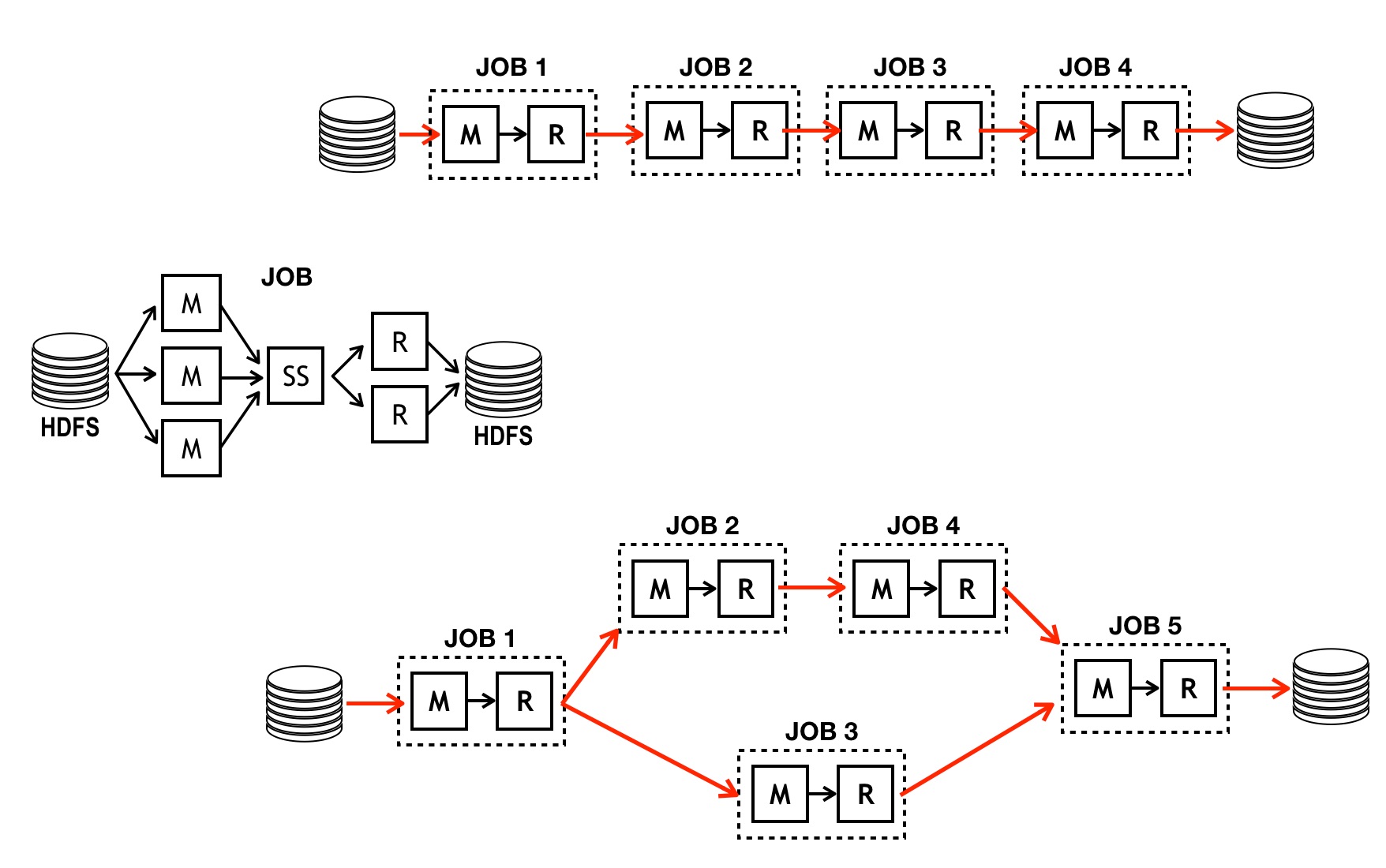
En el modelo computacional implementado en Hadoop, el mapper lee del sistema de archivos de Hadoop (HDFS) y el reducer escribe al sistema de archivos, ya que la cantidad de datos es tal que no podrían ser cargados a memoria.
Apache Spark#
Spark es un modelo computacional en el cual se elimina elimina a escritura a disco entre jobs (sólo se escribe cuando es necesario), lo que permite que el proceso se ejecute mucho más rápido. Sus principales componentes son las siguientes:
SparkRDD: opera sobre conjuntos de datos distribuidos mediante operaciones MapReduce.
SparkQL: Implementación del lenguaje SQL que puede ejecutarse sobre datos estructurados como tablas.
SparkML: Implementación de algoritmos de aprendizaje estadístico y aprendizaje automática que operan sobre datos estructurados como tablas.
Conteo de palabras usando SparkRDD#
A continuación se realiza el conteo de frecuencia de palabras usando SparkRDD. Se asume que Spark está ejecutándose en un cluster.
Movimiento de los archivos al HDFS#
Spark lee y escribe archivos en el sistema HDFS. Por lo tanto, es necesario transferir los datos del sistema local al HDFS. La gestión de archivos entre el sistema local y el HDFS se realiza mediante comandos similares a los del sistema operativo Unix en Terminal. A continuación se resumen los principales comandos.
hdfs dfs -help: Imprime la ayuda en pantalla para todos los comandos.
Gestion de directorios y archivos.
hdfs dfs -ls <path>hdfs dfs -mkdir <path>hdfs dfs -rmdir <path>hdfs dfs -cp <src> <dest>hdfs dfs -mv <src> <dest>hdfs dfs -rm <path>hdfs dfs -cat <path>hdfs dfs -head <path>hdfs dfs -tail <path>hdfs dfs -text <path>. Imprime el arachivo en<path>y lo imprime en formato texto. Soporta archivos zip, TextRecordInputStream y Avro.hdfs dfs -stat <path>: Imprime estadísticos de<path>.
Transferencia de información entre el sistema local y el HDFS.
hdfs dfs -get <src> <localdest>/hdfs dfs -copyToLocal <src> <localdest>. Copia el contenido de<src>en el HDFS en<localdest>en el sistema local.hdfs dfs -put <localsrc> <dest>/hdfs dfs -copyFromLocal <src> <localdest>. Copia el contenido de<localsrc>en el sistema local a<dest>en el HDFS.hdfs dfs -count <path>. Cuenta el número de directorios, archivos y bytes en<path>.hdfs dfs -appendToFile <localsrc> <dest>: pega al final de<dest>el contenido de los archivos en<localsrc>.
[5]:
#
# Se usan un directorio temporal en el HDFS. La siguiente
# instrucción muestra el contenido del dicho directorio
#
!hdfs dfs -ls /tmp
[6]:
#
# Crea la carpeta wordcount en el hdfs
#
!hdfs dfs -mkdir /tmp/wordcount
[7]:
#
# Verifica la creación de la carpeta
#
!hdfs dfs -ls /tmp/
Found 1 items
drwxr-xr-x - root supergroup 0 2022-05-27 14:38 /tmp/wordcount
[8]:
#
# Copia los archvios del directorio local wordcount/
# al directorio /tmp/wordcount/ en el hdfs
#
!hdfs dfs -copyFromLocal input /tmp/wordcount/
[9]:
#
# Verifica que los archivos esten copiados en el hdfs
#
!hdfs dfs -ls /tmp/wordcount
!hdfs dfs -ls /tmp/wordcount/input
Found 1 items
drwxr-xr-x - root supergroup 0 2022-05-27 14:38 /tmp/wordcount/input
Found 3 items
-rw-r--r-- 1 root supergroup 1093 2022-05-27 14:38 /tmp/wordcount/input/text0.txt
-rw-r--r-- 1 root supergroup 352 2022-05-27 14:38 /tmp/wordcount/input/text1.txt
-rw-r--r-- 1 root supergroup 440 2022-05-27 14:38 /tmp/wordcount/input/text2.txt
Implementación en PySpark#
La implementación en PySpark es la siguiente.
[10]:
#
# findspark: Permite usar PySpark como una libreria de Python
#
import findspark
findspark.init()
#
# Importa las librerias requeridas para conectar
# a Python con PySpark
#
from pyspark import SparkConf, SparkContext
#
# operador de agregación (MapReduce)
#
from operator import add
#
# Nombre de la aplicación en el cluster
#
APP_NAME = "My Spark Application"
#
# Configure Spark
#
conf = SparkConf().setAppName(APP_NAME)
sc = SparkContext(conf=conf)
sc.setLogLevel('ERROR')
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
[11]:
#
# Lee los archivos del hdfs y los carga a la variable text
#
text = sc.textFile("/tmp/wordcount/input/*.txt")
# Se imprimen las primeras 10 líneas
text.collect()[0:10]
[11]:
['Analytics is the discovery, interpretation, and communication of meaningful patterns ',
'in data. Especially valuable in areas rich with recorded information, analytics relies ',
'on the simultaneous application of statistics, computer programming and operations research ',
'to quantify performance.',
'',
'Organizations may apply analytics to business data to describe, predict, and improve business ',
'performance. Specifically, areas within analytics include predictive analytics, prescriptive ',
'analytics, enterprise decision management, descriptive analytics, cognitive analytics, Big ',
'Data Analytics, retail analytics, store assortment and stock-keeping unit optimization, ',
'marketing optimization and marketing mix modeling, web analytics, call analytics, speech ']
[12]:
#
# separa por palabras (split) con una palabra por registro
#
words = text.flatMap(lambda x: x.split())
# Se imprimen las primeras 10 palabras
words.collect()[0:10]
[12]:
['Analytics',
'is',
'the',
'discovery,',
'interpretation,',
'and',
'communication',
'of',
'meaningful',
'patterns']
[13]:
#
# Genera las parejas <clave, valor> representandolas
# com la tupla (word, 1)
#
wc = words.map(lambda x: (x,1))
wc.collect()[0:10]
[13]:
[('Analytics', 1),
('is', 1),
('the', 1),
('discovery,', 1),
('interpretation,', 1),
('and', 1),
('communication', 1),
('of', 1),
('meaningful', 1),
('patterns', 1)]
[14]:
#
# Suma los valores para la misma clave. Spark internamente ordena por claves
#
counts = wc.reduceByKey(add)
counts.collect()[0:10]
[14]:
[('interpretation,', 1),
('of', 8),
('in', 5),
('data.', 1),
('Especially', 1),
('analytics', 8),
('simultaneous', 1),
('operations', 1),
('research', 2),
('quantify', 1)]
[15]:
#
# Escribe los resultados al directorio `/tmp/output`
#
counts.saveAsTextFile("/tmp/wordcount/output")
Archivos de resultados#
Los resultados son escritos al HDFS.
[16]:
!hdfs dfs -ls /tmp/wordcount/
Found 2 items
drwxr-xr-x - root supergroup 0 2022-05-27 14:38 /tmp/wordcount/input
drwxr-xr-x - root supergroup 0 2022-05-27 14:39 /tmp/wordcount/output
[17]:
#
# Archivos con los resultados. Note que se
# generan varios archivos de resultados.
#
!hdfs dfs -ls /tmp/wordcount/output/
Found 5 items
-rw-r--r-- 1 root supergroup 0 2022-05-27 14:39 /tmp/wordcount/output/_SUCCESS
-rw-r--r-- 1 root supergroup 778 2022-05-27 14:39 /tmp/wordcount/output/part-00000
-rw-r--r-- 1 root supergroup 562 2022-05-27 14:39 /tmp/wordcount/output/part-00001
-rw-r--r-- 1 root supergroup 510 2022-05-27 14:39 /tmp/wordcount/output/part-00002
-rw-r--r-- 1 root supergroup 594 2022-05-27 14:39 /tmp/wordcount/output/part-00003
El archivo /tmp/output/_SUCCESS es un archivo vacio que indica que el programa fue ejecutado correctamente.
[18]:
!hdfs dfs -cat /tmp/wordcount/output/part-00000
('interpretation,', 1)
('of', 8)
('in', 5)
('data.', 1)
('Especially', 1)
('analytics', 8)
('simultaneous', 1)
('operations', 1)
('research', 2)
('quantify', 1)
('Organizations', 1)
('may', 1)
('business', 4)
('predict,', 1)
('include', 1)
('decision', 1)
('descriptive', 1)
('store', 1)
('optimization,', 2)
('modeling,', 2)
('speech', 1)
('promotion', 1)
('risk', 1)
('fraud', 1)
('Since', 1)
('algorithms', 1)
('used', 3)
('harness', 1)
('current', 1)
('field', 1)
('involves', 1)
('studying', 1)
('potential', 1)
('trends,', 1)
('performance', 1)
('goal', 1)
('changes.', 1)
('process', 1)
('draw', 1)
('specialized', 1)
('systems', 1)
('software.', 1)
('techniques', 1)
('are', 1)
('commercial', 1)
('organizations', 1)
('disprove', 1)
('scientific', 1)
('hypotheses.', 1)
Movimiento de los archivos de resultados a la máquina local#
[19]:
#
# Copia los archivos de resultados a la maquina local
#
!mkdir -p output
!hdfs dfs -getmerge /tmp/wordcount/output/* output/results.txt
[20]:
!head output/results.txt
('interpretation,', 1)
('of', 8)
('in', 5)
('data.', 1)
('Especially', 1)
('analytics', 8)
('simultaneous', 1)
('operations', 1)
('research', 2)
('quantify', 1)
Limpieza de las carpetas de trabajo
[21]:
!rm -rf input
!rm -rf output
!hdfs dfs -rm -r -f /tmp/wordcount/
Deleted /tmp/wordcount