WordCount usando Structured Streaming#
Este tutorial es adaptado de https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
Este tutorial introduce el uso de Spark para el manejo de streamings estructurados. Específicamente, se presenta un ejemplo de conteo de letras que es realizado a medida que estas son introducidas por un usuario desde el teclado en una consola.
Al finalizar este tutorial, usted estará en capacidad de:
Explicar los fundamentos del procesamiento de datos en streaming usando Spark.
Escribir programas cortos para procesar datos.
Aplicar operaciones básicas en Spark para manejo de tablas.
Definición del problema#
Se desea realizar el conteo de frecuencia de palabras en tiempo real, a partir de frases o letras digitas obtenidas desde un puerto en el sistema operativo.
Solución#
Conteo de palabras en PySpark#
En esta sección se revisará como contar palabras de la forma tradicional usando SparkSQL, las cuales están almacenadas y representadas como letras en el siguiente archivo de texto:
[1]:
%%writefile words.txt
value
A B C A
A B A A
Overwriting words.txt
[2]:
##
## Se copia el archivo al HDFS
##
!hdfs dfs -rm -f /tmp/words.txt
!hdfs dfs -copyFromLocal words.txt /tmp/words.txt
Deleted /tmp/words.txt
[3]:
##
## Se inicia la aplicación en PySpark
##
import findspark
findspark.init()
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
sparkConf = SparkConf().setAppName("My SparkQL Application")
sc = SparkContext(conf=sparkConf)
spark = SparkSession(sc)
[4]:
##
## Se lee el archivo del hdfs en formato CSV.
## Cada fila del DataFrame es un renglón del archivo
##
df = spark.read.load(
"/tmp/words.txt",
format="csv",
sep=",",
inferSchema="true",
header="true")
df.show()
+-------+
| value|
+-------+
|A B C A|
|A B A A|
+-------+
[5]:
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
##
## La función split parte cada línea de texto por los espacios en
## blanco, retornando un vector; por ejemplo, para la primera
## línea retorna ['A', 'B', 'C', 'A']. Seguidamente, la función
## explode genera un registro por cada elemento del vector, tal
## como se muestra a continuación.
##
words = df.select(
explode(
split(df.value, " ")
).alias("word")
)
words.show()
+----+
|word|
+----+
| A|
| B|
| C|
| A|
| A|
| B|
| A|
| A|
+----+
[6]:
##
## Para realizar el conteo propiamente, se realizar un
## groupBy por letra, y se cuenta la cantidad de registros
## por grupo usando la función `count`.
##
wordCounts = words.groupBy("word").count()
wordCounts.show()
+----+-----+
|word|count|
+----+-----+
| B| 2|
| C| 1|
| A| 5|
+----+-----+
[7]:
##
## Se finaliza la aplicación
##
spark.stop()
Conteo de palabras usando Spark Streaming#
A continuación se realizar el conteo de palabras leyendo los datos desde un streaming.
Las diferencias con el ejemplo anterior están comentadas en el código. Note que se está creando un archivo, con el fin de ejecutar el programa por fuera de Jupyter.
[8]:
%%writefile wc-pyspark.py
## Identico ------>>>
import findspark
findspark.init()
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
spark = SparkSession \
.builder \
.appName("StructuredNetworkWordCount") \
.getOrCreate()
## <<<------
##
## Los datos se leen desde un flujo de entrada en vez de un archivo
## en disco. Para ello, se crea un DataFrame que representa las líneas
## de texto de entrada, las cuales son leídas desde una conexión a
## localhost:9999. El flujo de datos puede considerarse como un DataFrame
## infinito, donde los nuevos datos se van adicionando al final.
##
df = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.load()
## Identico ------>>>
words = df.select(
explode(
split(df.value, " ")
).alias("word")
)
wordCounts = words.groupBy("word").count()
## <<<------
##
## Crea un stream de salida a la consola, en la que se van
## escribiendo los resultados a medida que se van ingresando
## datos.
##
query = wordCounts \
.writeStream \
.outputMode("complete") \
.format("console") \
.start()
query.awaitTermination()
Overwriting wc-pyspark.py
Ejecución de la aplicación#
Para ejecutar el programa se requieren dos consolas; en la primera se ejecuta el comando nc -lk 9999, el cual crea un servidor de datos interactivo que usa el puerto 9999 (que es el mismo puerto que está escuchando la aplicación de conteo de palabras). En la segunda consola, se ejecuta la aplicación.
Paso 1#
Abrá un Terminal y ejecute el comando nc -lk 9999. El Terminal quedará en espera para que ingrese texto.
Paso 2#
Abra otro Terminal y ejecute el comando spark-submit wc-pyspark.py para lanzar la aplicación de conteo de palabras.
Su pantalla debe mostrar una salida similar a la siguiente:

Paso 3#
Digite A B C A y luego la tecla enter; después de un momento, la aplicación reportará el conteo preliminar de letras:

Paso 4#
Digite la segunda línea de texto A B A A; luego aparecerá el conteo actualizado de letras.

Paso 5#
Finalice las aplicaciones.
### Programa equivalente en SparkR
A continuación se presenta el código equivalente en SparkR.
[9]:
%%writefile wc-sparkR.R
library(SparkR)
sparkR.session()
df <- read.stream(
"socket",
host = "localhost",
port = 9999)
words <- selectExpr(
df,
"explode(split(value, ' ')) as word")
wordCounts <- count(group_by(words, "word"))
query <- write.stream(
wordCounts,
"console",
outputMode = "complete")
awaitTermination(query)
sparkR.session.stop()
Overwriting wc-sparkR.R
Para ejecutar el programa en R, use spark-submit wc-sparkR.R en el Paso 2 del ejemplo presentado.
### Descripción del modelo de programación
A continuación se describe en detalle el modelo de programación con base en el ejemplo presentado.
Flujo de datos de entrada#
El flujo de datos de entrada (readStream), creado en la siguiente porción de código:
df = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.load()
puede interpretarse como un DataFrame infinito, donde los nuevos datos se van agragando al final de la tabla, tal como se indica a continuación:
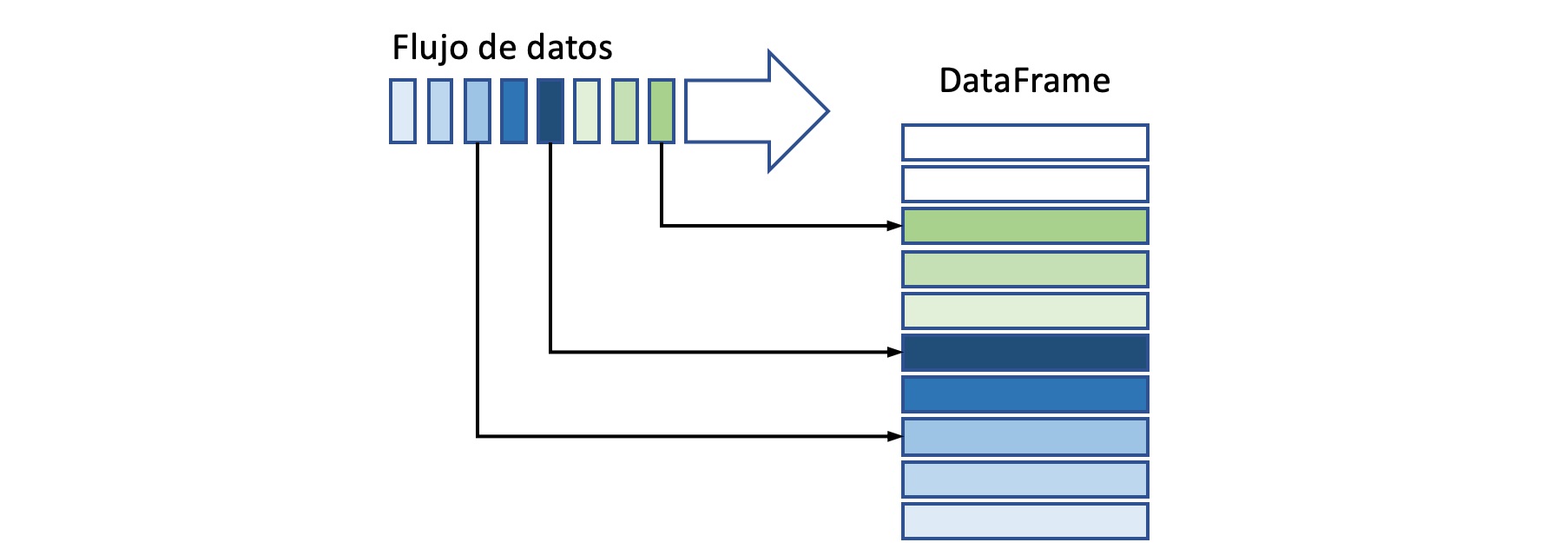
Operaciones sobre el flujo de entrada#
Las operaciones realizadas en el DataFrame son similares a las usadas en los DataFrames estáticos, tal como se muestra a continuación:
words = df.select(
explode(
split(df.value, " ")
).alias("word")
)
wordCounts = words.groupBy("word").count()
con la única diferencia que Spark sigue revisando el flujo de entrada para determinar si existen más datos. En este modelo computacional, Spark combina de forma automática los resultados de un instante anterior, con los obtenidos para los nuevos datos procesados.
Tipos de entradas#
Spark usa cuatro tipos de fuentes de entrada:
File source: Spark lee los archivos que se van colocando en un directorio como un stream de datos usando el objeto
DataStreamReader. Los archivos pueden tener formato csv, json, orc o parquet.Kafka source: Lee datos generados mediante Apache Kafka.
Socket source: Lee texto desde un puerto (socket) y es usado únicamente para pruebas. Esta es la fuente usada en el ejemplo presentado.
Rate source: Genera datos a un número específico de filas por segundo, donde cada fila tiene un campo de tiempo (
timestamp) y un campo valor.
Flujo de salida#
La siguiente porción de código define como se escribirán los resultados (outputMode) en el flujo de salida (writeStream):
query = wordCounts \
.writeStream \
.outputMode("complete") \
.format("console") \
.start()
complete: La tabla resultante
wordCountses escrita completamente en la consola cuando es actualizada. Esta es el tipo de salida usada en el ejemplo presentado.append: Solo se escriben las nuevas filas que se van generando en la tabla resultante
wordCounts. Este modo se usa sólo cuando las filas creadas no cambian posteriormente.update: Se escriben solo las filas que se actualiza en la tabla de salida.
Formato de salida#
Spark proporciona los siguientes formatos de salida:
File sink: Los resultados son escritos a un archivo en formato csv, orc, json o parquet; por ejemplo:
writeStream
.format("parquet")
.option("path", "path/to/destination/dir")
.start()
Kafka sink: Almacena el resultado usando Apache Kafka.
Foreach sink: Realiza cómputos arbitrarios sobre los registros de la salida.
Console sink: Esta es una salida usada únicamente para depuración y permite la escritura del DataFrame de salida en el Terminal. Este es el tipo de salida usado en el ejemplo desarrollado.
writeStream
.format("console")
.start()
Memory sink: El resultado es almacenado como una tabla en memoria, y se usa únicamente en la depuración de programas.
Triggers#
Definen el intervalo de procesamiento del stream de datos.
Unspecified: Este el el intervalo por defecto. El stream es procesado por microlotes, donde cada microlote es procesado tan pronto como el microlote anterior es terminado. Un microlote está conformado por un grupo de registros a la vez. Por ejemplo:
## En PySpark
df.writeStream \
.format("console") \
.start()
## En SparkR
write.stream(df, "console")
Fixed interval micro-batches: Los microlotes están conformados por los registros recolectados en un intervalo fijo de tiempo, por ejemplo, todos los registros que llegan en un intervalo de dos segundos:
## En PySpark
df.writeStream \
.format("console") \
.trigger(processingTime='2 seconds') \
.start()
## En SparkR
write.stream(df, "console", trigger.processingTime = "2 seconds")
One-time micro-batch: El proceso es ejecutado una sola vez, con todos los registros disponibles. Se usa cuando el procesamiento debe realizarse periodicamente. El codigo correspondiente en Python sería:
## En PySpark
df.writeStream \
.format("console") \
.trigger(once=True) \
.start()
## En SparkR
write.stream(df, "console", trigger.once = TRUE)
Continuous with fixed checkpoint interval (experimental): El proceso es ejecutado a intervalos muy bajos de tiempo, simulando un proceso continuo.
## En PySpark
df.writeStream
.format("console")
.trigger(continuous='1 second')
.start()