UI Workflow#
Ultima modificación: Mayo 14, 2022
Diretorio para almacenar el proyecto#
[1]:
#
# Borra el directorio de trabajo
#
!rm -rf mlruns
!rm mlruns.db
rm: mlruns.db: No such file or directory
Codebase#
[2]:
# ---------------------------------------------------------------------------------------
#
# Este código es identico al de los ejemplos anteriores
#
# ---------------------------------------------------------------------------------------
def load_data():
import pandas as pd
url = "https://raw.githubusercontent.com/jdvelasq/datalabs/master/datasets/concrete.csv"
df = pd.read_csv(url)
df = df.astype({'age': 'float'})
y = df["strength"]
x = df.copy()
x.pop("strength")
return x, y
def make_train_test_split(x, y):
from sklearn.model_selection import train_test_split
(x_train, x_test, y_train, y_test) = train_test_split(
x,
y,
test_size=0.25,
random_state=123456,
)
return x_train, x_test, y_train, y_test
def eval_metrics(y_true, y_pred):
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
mse = mean_squared_error(y_true, y_pred)
mae = mean_absolute_error(y_true, y_pred)
r2 = r2_score(y_true, y_pred)
return mse, mae, r2
def report(estimator, mse, mae, r2):
print(estimator, ":", sep="")
print(f" MSE: {mse}")
print(f" MAE: {mae}")
print(f" R2: {r2}")
def log_metrics(mse, mae, r2):
import mlflow
mlflow.log_metric("mse", mse)
mlflow.log_metric("mae", mae)
mlflow.log_metric("r2", r2)
def make_pipeline(estimator):
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler
pipeline = Pipeline(
steps=[
("minMaxScaler", MinMaxScaler()),
("estimator", estimator),
],
)
return pipeline
def set_tracking_uri():
import mlflow
mlflow.set_tracking_uri('sqlite:///mlruns.db')
def display_config():
import mlflow
print("Current model registry uri: {}".format(mlflow.get_registry_uri()))
print(" Current tracking uri: {}".format(mlflow.get_tracking_uri()))
#
# Modelos
#
def make_linear_regression():
import sys
from sklearn.linear_model import LinearRegression
import mlflow
x, y = load_data()
x_train, x_test, y_train, y_test = make_train_test_split(x, y)
mlflow.sklearn.autolog()
estimator = make_pipeline(
estimator=LinearRegression(),
)
with mlflow.start_run():
estimator.fit(x_train, y_train)
mse, mae, r2 = eval_metrics(
y_true=y_test,
y_pred=estimator.predict(x_test),
)
log_metrics(mse, mae, r2)
report(estimator, mse, mae, r2)
def make_k_neighbors_regressor(n_neighbors):
import sys
from sklearn.neighbors import KNeighborsRegressor
import mlflow
x, y = load_data()
x_train, x_test, y_train, y_test = make_train_test_split(x, y)
mlflow.sklearn.autolog()
estimator = make_pipeline(
estimator=KNeighborsRegressor(n_neighbors=n_neighbors),
)
with mlflow.start_run():
estimator.fit(x_train, y_train)
mse, mae, r2 = eval_metrics(
y_true=y_test,
y_pred=estimator.predict(x_test),
)
log_metrics(mse, mae, r2)
report(estimator, mse, mae, r2)
Ejecución de los experimentos#
[3]:
set_tracking_uri()
display_config()
Current model registry uri: sqlite:///mlruns.db
Current tracking uri: sqlite:///mlruns.db
[4]:
make_linear_regression()
2022/06/03 22:48:44 WARNING mlflow.utils.autologging_utils: MLflow autologging encountered a warning: "/Volumes/GitHub/courses-source/notebooks/mlflow/.venv/lib/python3.8/site-packages/setuptools/distutils_patch.py:25: UserWarning: Distutils was imported before Setuptools. This usage is discouraged and may exhibit undesirable behaviors or errors. Please use Setuptools' objects directly or at least import Setuptools first."
2022/06/03 22:48:45 INFO mlflow.store.db.utils: Creating initial MLflow database tables...
2022/06/03 22:48:45 INFO mlflow.store.db.utils: Updating database tables
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Running upgrade -> 451aebb31d03, add metric step
INFO [alembic.runtime.migration] Running upgrade 451aebb31d03 -> 90e64c465722, migrate user column to tags
INFO [alembic.runtime.migration] Running upgrade 90e64c465722 -> 181f10493468, allow nulls for metric values
INFO [alembic.runtime.migration] Running upgrade 181f10493468 -> df50e92ffc5e, Add Experiment Tags Table
INFO [alembic.runtime.migration] Running upgrade df50e92ffc5e -> 7ac759974ad8, Update run tags with larger limit
INFO [alembic.runtime.migration] Running upgrade 7ac759974ad8 -> 89d4b8295536, create latest metrics table
INFO [89d4b8295536_create_latest_metrics_table_py] Migration complete!
INFO [alembic.runtime.migration] Running upgrade 89d4b8295536 -> 2b4d017a5e9b, add model registry tables to db
INFO [2b4d017a5e9b_add_model_registry_tables_to_db_py] Adding registered_models and model_versions tables to database.
INFO [2b4d017a5e9b_add_model_registry_tables_to_db_py] Migration complete!
INFO [alembic.runtime.migration] Running upgrade 2b4d017a5e9b -> cfd24bdc0731, Update run status constraint with killed
INFO [alembic.runtime.migration] Running upgrade cfd24bdc0731 -> 0a8213491aaa, drop_duplicate_killed_constraint
INFO [alembic.runtime.migration] Running upgrade 0a8213491aaa -> 728d730b5ebd, add registered model tags table
INFO [alembic.runtime.migration] Running upgrade 728d730b5ebd -> 27a6a02d2cf1, add model version tags table
INFO [alembic.runtime.migration] Running upgrade 27a6a02d2cf1 -> 84291f40a231, add run_link to model_version
INFO [alembic.runtime.migration] Running upgrade 84291f40a231 -> a8c4a736bde6, allow nulls for run_id
INFO [alembic.runtime.migration] Running upgrade a8c4a736bde6 -> 39d1c3be5f05, add_is_nan_constraint_for_metrics_tables_if_necessary
INFO [alembic.runtime.migration] Running upgrade 39d1c3be5f05 -> c48cb773bb87, reset_default_value_for_is_nan_in_metrics_table_for_mysql
INFO [alembic.runtime.migration] Running upgrade c48cb773bb87 -> bd07f7e963c5, create index on run_uuid
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
Pipeline(steps=[('minMaxScaler', MinMaxScaler()),
('estimator', LinearRegression())]):
MSE: 117.25636031414096
MAE: 8.526872668000976
R2: 0.6007675607096427
[5]:
#
# Ejecución del modelo de vecinos más cercanos
#
for n_neighbors in range(1, 5):
print(f"----------------------------- neighbors = {n_neighbors} -----------------------------")
make_k_neighbors_regressor(n_neighbors)
print()
----------------------------- neighbors = 1 -----------------------------
Pipeline(steps=[('minMaxScaler', MinMaxScaler()),
('estimator', KNeighborsRegressor(n_neighbors=1))]):
MSE: 84.29744651162792
MAE: 6.566356589147286
R2: 0.712985503672273
----------------------------- neighbors = 2 -----------------------------
Pipeline(steps=[('minMaxScaler', MinMaxScaler()),
('estimator', KNeighborsRegressor(n_neighbors=2))]):
MSE: 75.76470591085271
MAE: 6.5040503875969
R2: 0.7420376321431968
----------------------------- neighbors = 3 -----------------------------
Pipeline(steps=[('minMaxScaler', MinMaxScaler()),
('estimator', KNeighborsRegressor(n_neighbors=3))]):
MSE: 80.3410048664944
MAE: 6.792235142118863
R2: 0.7264563281517714
----------------------------- neighbors = 4 -----------------------------
Pipeline(steps=[('minMaxScaler', MinMaxScaler()),
('estimator', KNeighborsRegressor(n_neighbors=4))]):
MSE: 84.93929769864341
MAE: 6.951056201550387
R2: 0.7108001397878143
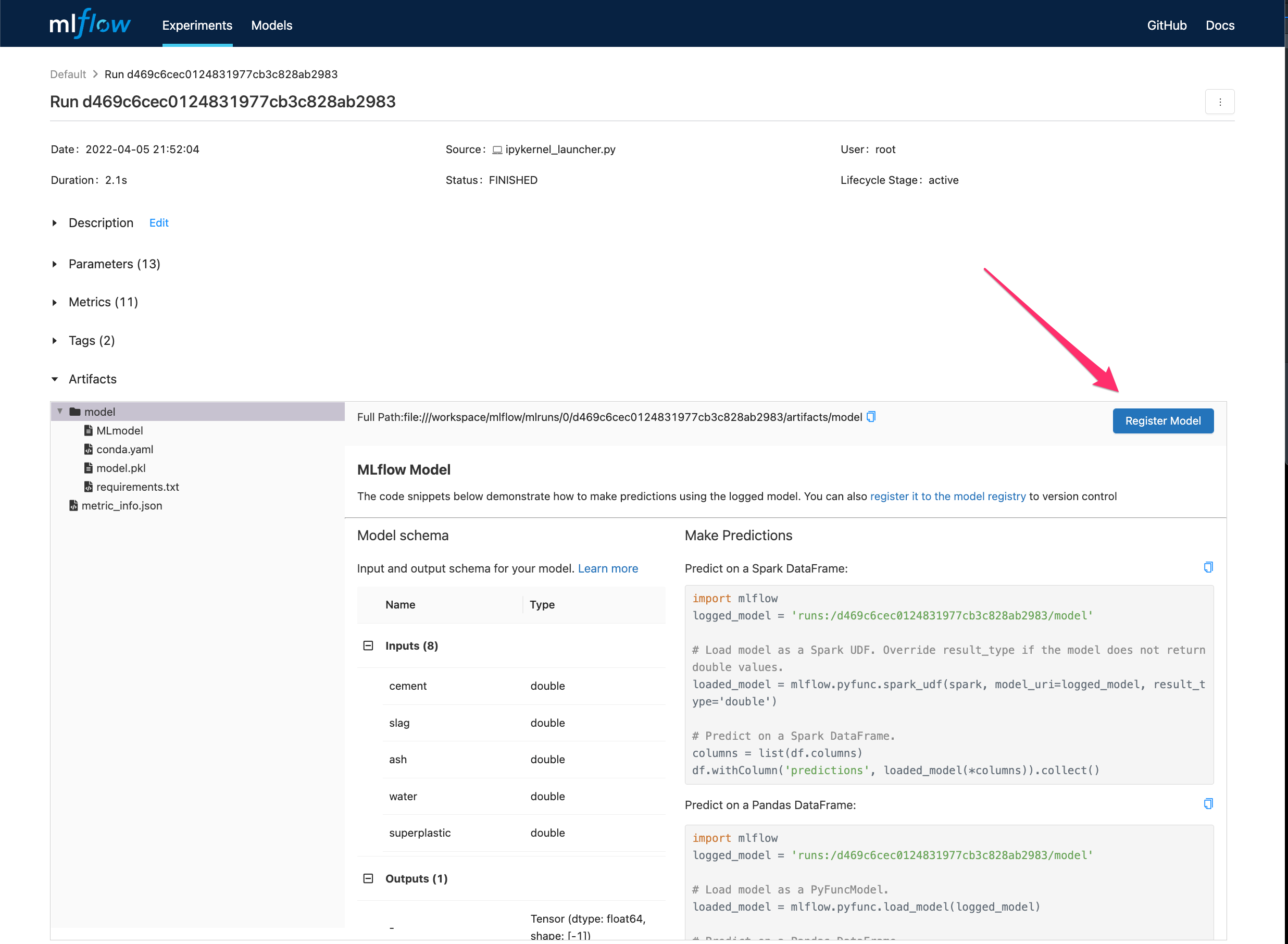
MLflow ui#
Para visualizar la interfase use:
mlflow ui --backend-store-uri sqlite:///mlruns.db
Nota: En docker usar:
mlflow ui --host 0.0.0.0 --backend-store-uri sqlite:///mlruns.db
con:
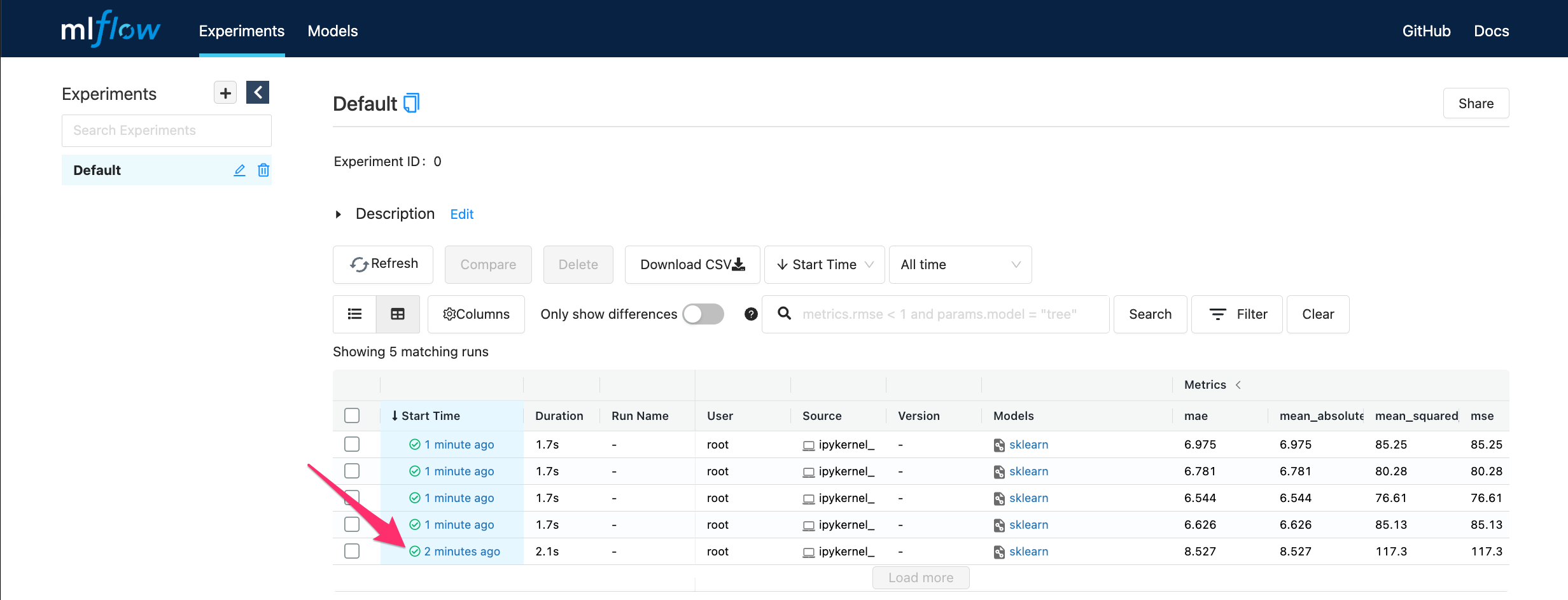
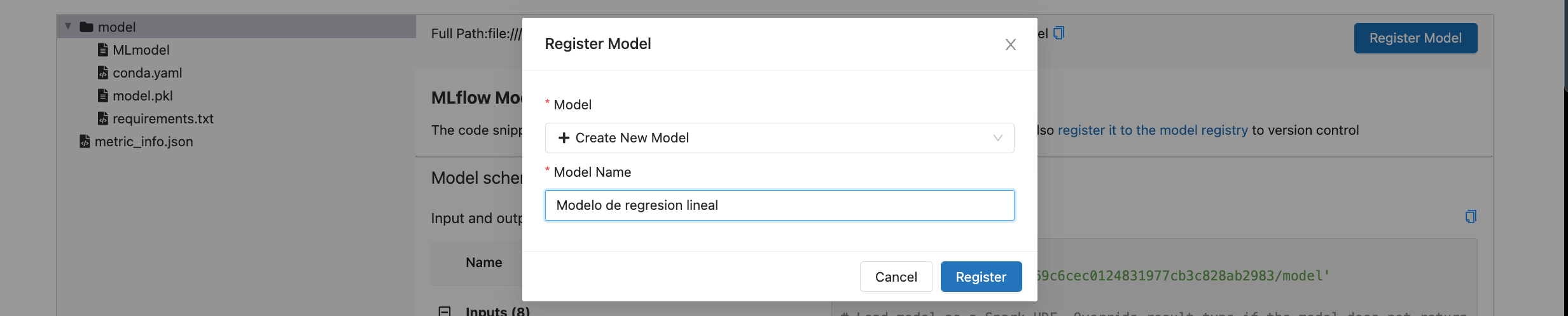
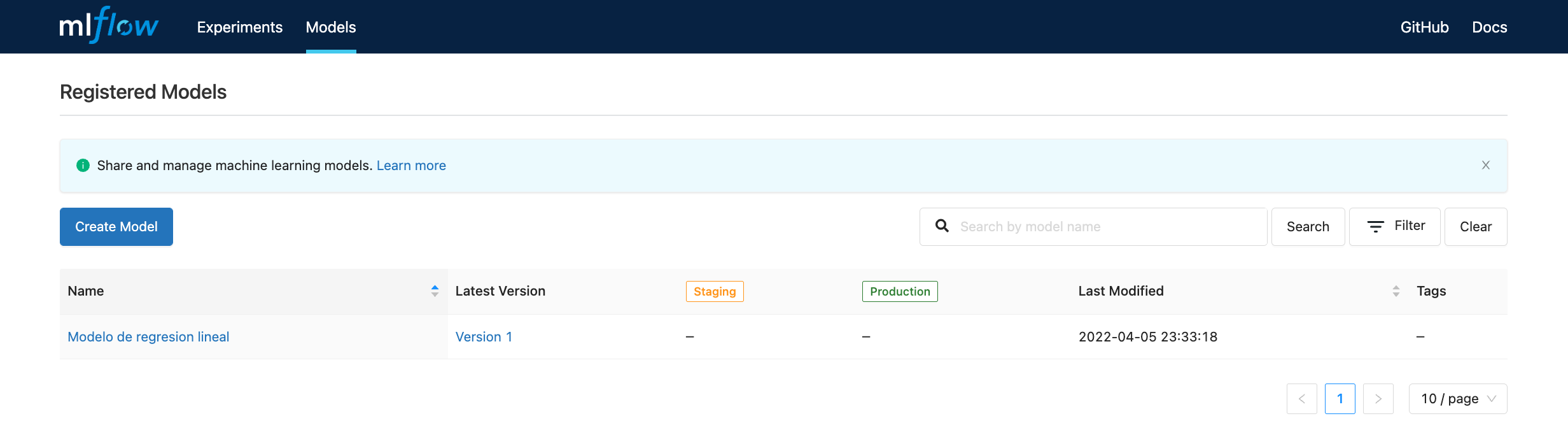
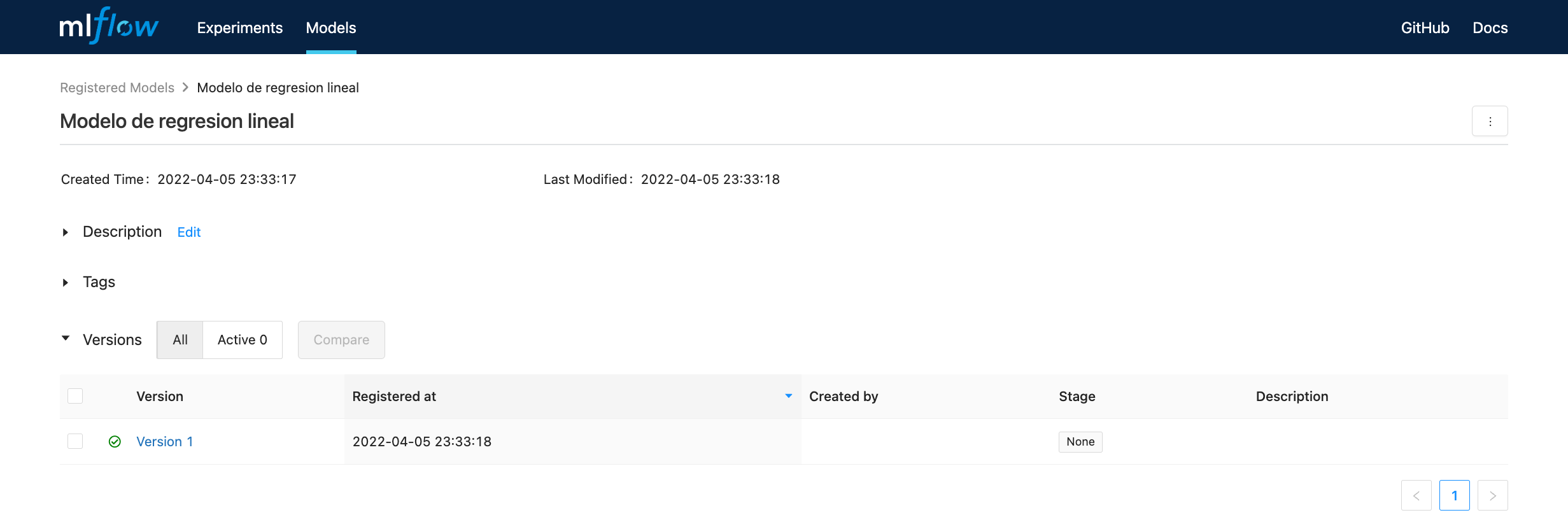
Modelo