Caso de Estudio: Graficación de Precios de Bolsa con ChatGPT#
Ultima modificación: Feb 04, 2024 | YouTube
La url ‘https://raw.githubusercontent.com/jdvelasq/datalabs/master/datasets/precio_bolsa_nacional/csv/*.csv’ contiene los archivos de los precios horarios de bolsa para el mercado electrico colombiano. Construya una gráfica que contenga los precios promedios diarios y los precios promedios mensuales.
Paso 1#
Prompt: I want you to act as a python programmer assistant.
Write the code to obtain the filenames in a github repo with owner=”jdvelasq”, repo=”datalabs”, and folder=”datasets/precio_bolsa_nacional/csv/”.
Do not explain the code.
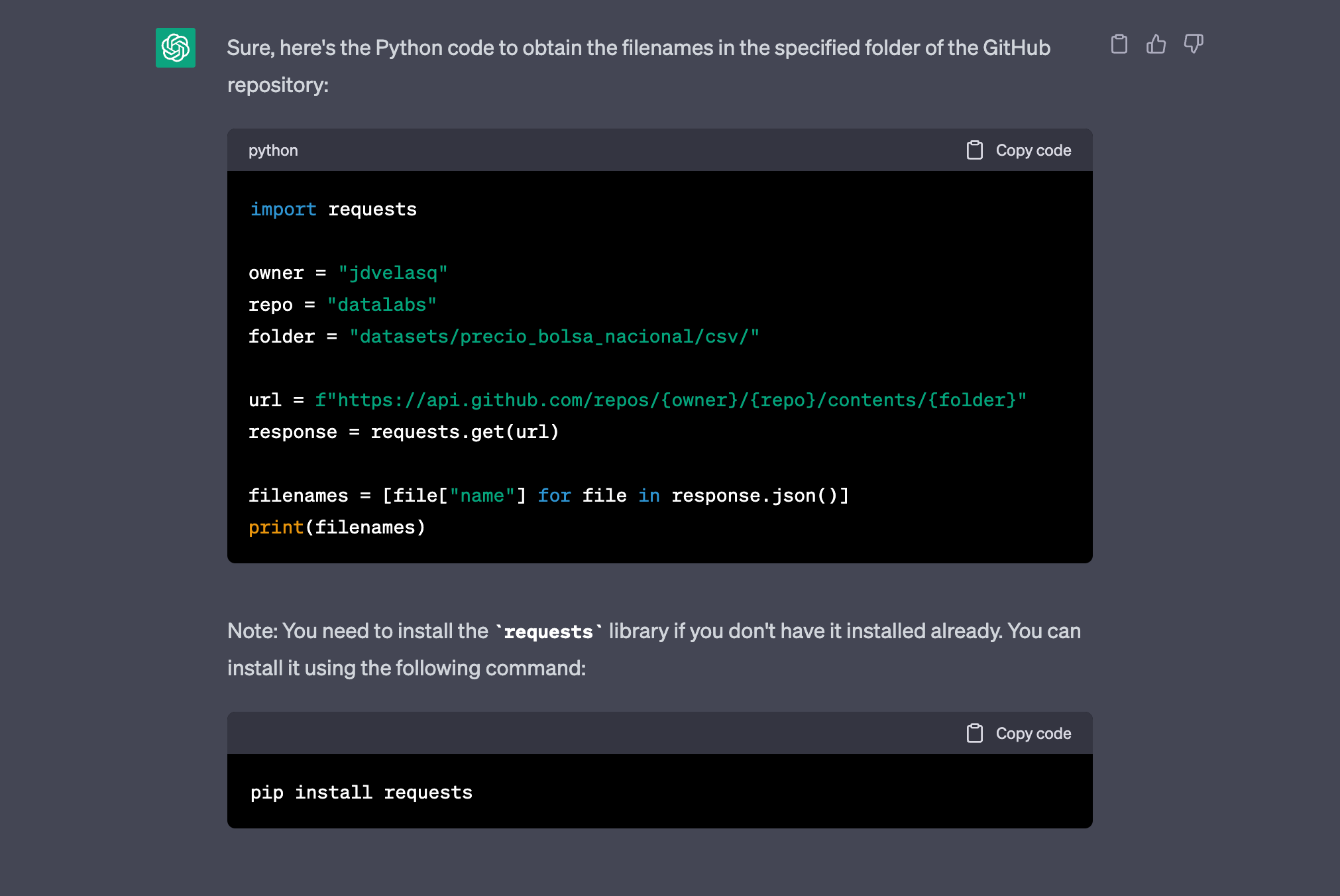
[1]:
import requests
owner = "jdvelasq"
repo = "datalabs"
folder = "datasets/precio_bolsa_nacional/csv/"
url = f"https://api.github.com/repos/{owner}/{repo}/contents/{folder}"
response = requests.get(url)
filenames = [file["name"] for file in response.json()]
print(filenames)
['199507.csv', '199508.csv', '199509.csv', '199510.csv', '199511.csv', '199512.csv', '199601.csv', '199602.csv', '199603.csv', '199604.csv', '199605.csv', '199606.csv', '199607.csv', '199608.csv', '199609.csv', '199610.csv', '199611.csv', '199612.csv', '199701.csv', '199702.csv', '199703.csv', '199704.csv', '199705.csv', '199706.csv', '199707.csv', '199708.csv', '199709.csv', '199710.csv', '199711.csv', '199712.csv', '199801.csv', '199802.csv', '199803.csv', '199804.csv', '199805.csv', '199806.csv', '199807.csv', '199808.csv', '199809.csv', '199810.csv', '199811.csv', '199812.csv', '199901.csv', '199902.csv', '199903.csv', '199904.csv', '199905.csv', '199906.csv', '199907.csv', '199908.csv', '199909.csv', '199910.csv', '199911.csv', '199912.csv', '200001.csv', '200002.csv', '200003.csv', '200004.csv', '200005.csv', '200006.csv', '200007.csv', '200008.csv', '200009.csv', '200010.csv', '200011.csv', '200012.csv', '200101.csv', '200102.csv', '200103.csv', '200104.csv', '200105.csv', '200106.csv', '200107.csv', '200108.csv', '200109.csv', '200110.csv', '200111.csv', '200112.csv', '200201.csv', '200202.csv', '200203.csv', '200204.csv', '200205.csv', '200206.csv', '200207.csv', '200208.csv', '200209.csv', '200210.csv', '200211.csv', '200212.csv', '200301.csv', '200302.csv', '200303.csv', '200304.csv', '200305.csv', '200306.csv', '200307.csv', '200308.csv', '200309.csv', '200310.csv', '200311.csv', '200312.csv', '200401.csv', '200402.csv', '200403.csv', '200404.csv', '200405.csv', '200406.csv', '200407.csv', '200408.csv', '200409.csv', '200410.csv', '200411.csv', '200412.csv', '200501.csv', '200502.csv', '200503.csv', '200504.csv', '200505.csv', '200506.csv', '200507.csv', '200508.csv', '200509.csv', '200510.csv', '200511.csv', '200512.csv', '200601.csv', '200602.csv', '200603.csv', '200604.csv', '200605.csv', '200606.csv', '200607.csv', '200608.csv', '200609.csv', '200610.csv', '200611.csv', '200612.csv', '200701.csv', '200702.csv', '200703.csv', '200704.csv', '200705.csv', '200706.csv', '200707.csv', '200708.csv', '200709.csv', '200710.csv', '200711.csv', '200712.csv', '200801.csv', '200802.csv', '200803.csv', '200804.csv', '200805.csv', '200806.csv', '200807.csv', '200808.csv', '200809.csv', '200810.csv', '200811.csv', '200812.csv', '200901.csv', '200902.csv', '200903.csv', '200904.csv', '200905.csv', '200906.csv', '200907.csv', '200908.csv', '200909.csv', '200910.csv', '200911.csv', '200912.csv', '201001.csv', '201002.csv', '201003.csv', '201004.csv', '201005.csv', '201006.csv', '201007.csv', '201008.csv', '201009.csv', '201010.csv', '201011.csv', '201012.csv', '201101.csv', '201102.csv', '201103.csv', '201104.csv', '201105.csv', '201106.csv', '201107.csv', '201108.csv', '201109.csv', '201110.csv', '201111.csv', '201112.csv', '201201.csv', '201202.csv', '201203.csv', '201204.csv', '201205.csv', '201206.csv', '201207.csv', '201208.csv', '201209.csv', '201210.csv', '201211.csv', '201212.csv', '201301.csv', '201302.csv', '201303.csv', '201304.csv', '201305.csv', '201306.csv', '201307.csv', '201308.csv', '201309.csv', '201310.csv', '201311.csv', '201312.csv', '201401.csv', '201402.csv', '201403.csv', '201404.csv', '201405.csv', '201406.csv', '201407.csv', '201408.csv', '201409.csv', '201410.csv', '201411.csv', '201412.csv', '201501.csv', '201502.csv', '201503.csv', '201504.csv', '201505.csv', '201506.csv', '201507.csv', '201508.csv', '201509.csv', '201510.csv', '201511.csv', '201512.csv', '201601.csv', '201602.csv', '201603.csv', '201604.csv', '201605.csv', '201606.csv', '201607.csv', '201608.csv', '201609.csv', '201610.csv', '201611.csv', '201612.csv', '201701.csv', '201702.csv', '201703.csv', '201704.csv', '201705.csv', '201706.csv', '201707.csv', '201708.csv', '201709.csv', '201710.csv', '201711.csv', '201712.csv', '201801.csv', '201802.csv', '201803.csv', '201804.csv', '201805.csv', '201806.csv', '201807.csv', '201808.csv', '201809.csv', '201810.csv', '201811.csv', '201812.csv', '201901.csv', '201902.csv', '201903.csv', '201904.csv', '201905.csv', '201906.csv', '201907.csv', '201908.csv', '201909.csv', '201910.csv', '201911.csv', '201912.csv', '202001.csv', '202002.csv', '202003.csv', '202004.csv', '202005.csv', '202006.csv', '202007.csv', '202008.csv', '202009.csv', '202010.csv', '202011.csv', '202012.csv', '202101.csv', '202102.csv', '202103.csv', '202104.csv']
Paso 2#
Prompt: I want you to act as a python programmer assistant.
Write the code to read with pandas the CSV filenames in the master branch of the github repo with owner=”jdvelasq”, repo=”datalabs”, and folder=”datasets/precio_bolsa_nacional/csv”. Next, concatenate the dataframes.
Do not explain the code.
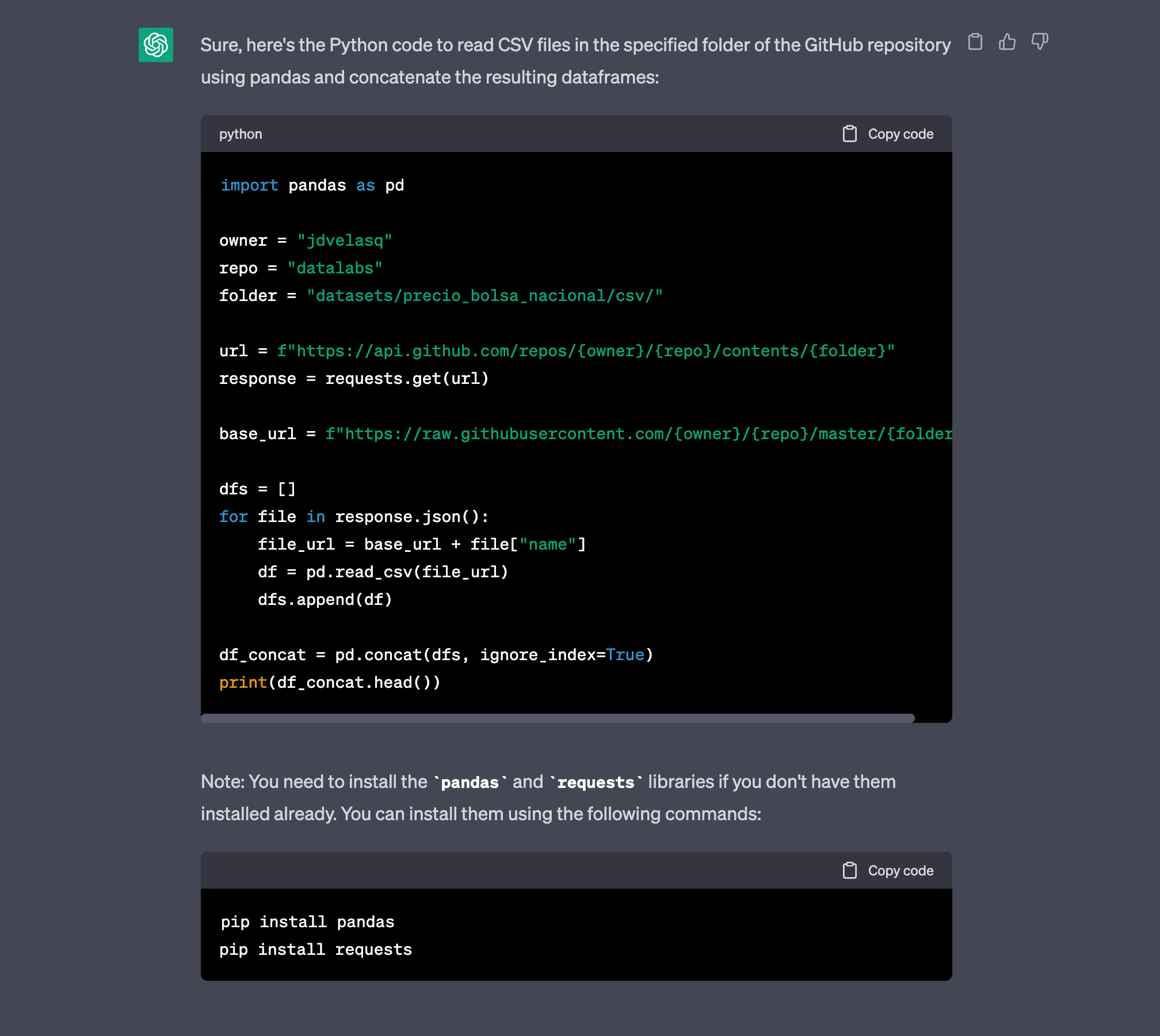
[2]:
import pandas as pd
owner = "jdvelasq"
repo = "datalabs"
folder = "datasets/precio_bolsa_nacional/csv/"
url = f"https://api.github.com/repos/{owner}/{repo}/contents/{folder}"
response = requests.get(url)
base_url = f"https://raw.githubusercontent.com/{owner}/{repo}/master/{folder}"
dfs = []
for file in response.json():
file_url = base_url + file["name"]
df = pd.read_csv(file_url)
dfs.append(df)
df_concat = pd.concat(dfs, ignore_index=True)
print(df_concat.head())
Fecha 0 1 2 3 4 5 6 7 8
0 1995-07-21 1.073 1.0 1.0 1.0 1.0 1.0 5.0 6.0 6.0 \
1 1995-07-22 1.073 1.073 1.0 1.0 1.0 1.073 1.303 1.303 1.303
2 1995-07-23 1.073 1.0 1.0 1.0 1.0 1.0 0.1 1.0 1.0
3 1995-07-24 1.0 1.0 0.99 1.0 1.0 1.073 3.0 3.0 3.0
4 1995-07-25 0.99 0.99 0.989 0.99 0.99 1.073 1.263 1.263 1.263
... 14 15 16 17 18 19 20 21 22 23
0 ... 5.0 1.0 1.0 5.0 12.0 16.67 11.929 5.0 1.0 1.0
1 ... 1.073 1.0 1.0 1.0 1.303 2.5 2.5 1.303 1.073 1.073
2 ... 1.0 0.1 0.1 1.0 1.238 1.238 1.238 1.238 1.073 1.0
3 ... 1.073 1.073 3.0 2.0 18.63 22.5 9.256 3.0 1.073 1.0
4 ... 1.073 1.073 1.073 1.073 1.263 1.5 1.263 1.263 1.073 0.99
[5 rows x 25 columns]
Paso 3#
Prompt: I want you to act as a python programmer assistant.
The previous dataframe called “df_concat” contains the column “Fecha” represent a date with format “YYYY-MM-DD”, and the columns “0” to “23” representing the hours of a day. Write a code to generate a dataframe with columns “Fecha”, hour, and value.
Do not explain the code.
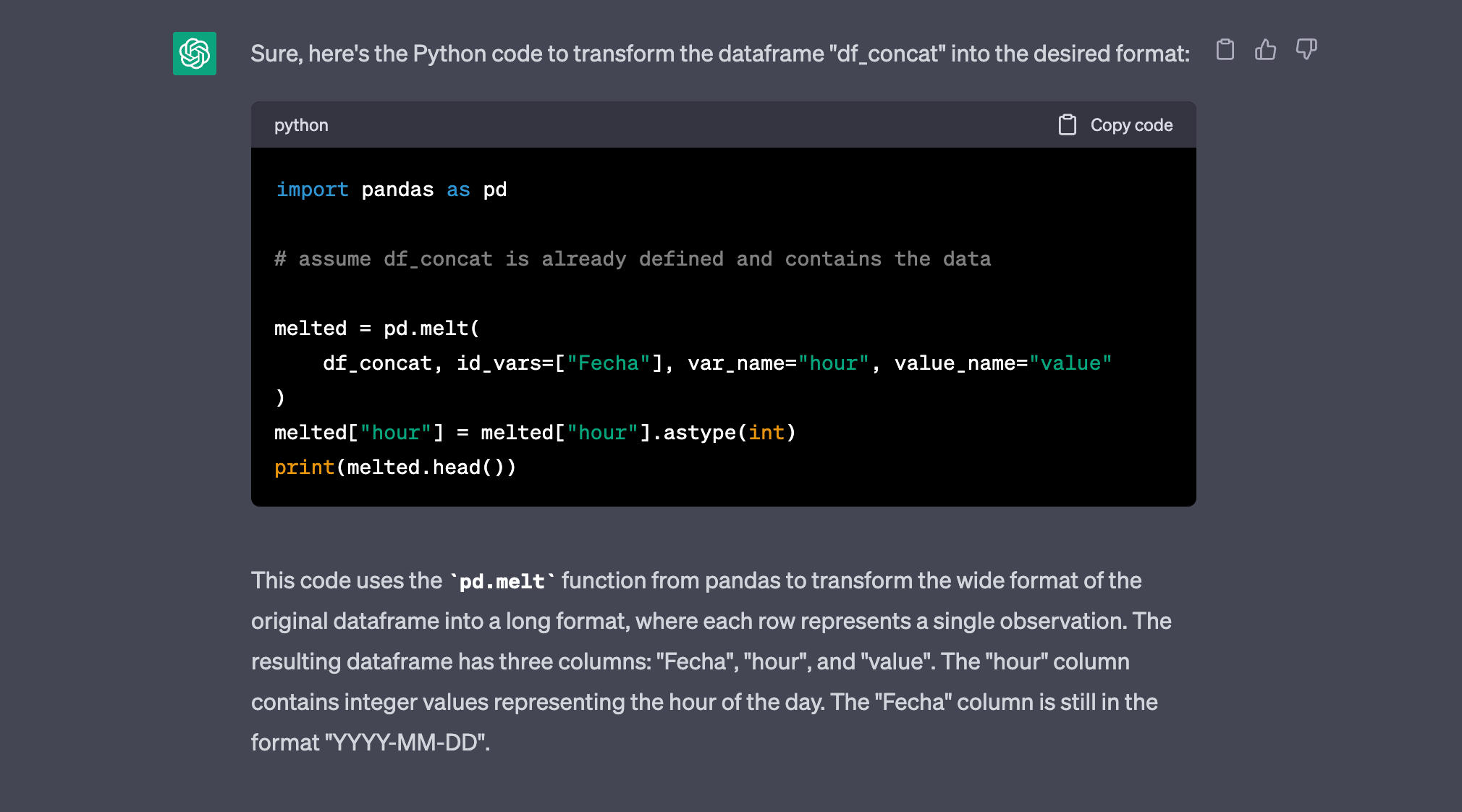
[3]:
import pandas as pd
melted = pd.melt(df_concat, id_vars=["Fecha"], var_name="hour", value_name="value")
melted["hour"] = melted["hour"].astype(int)
print(melted.head())
Fecha hour value
0 1995-07-21 0 1.073
1 1995-07-22 0 1.073
2 1995-07-23 0 1.073
3 1995-07-24 0 1.0
4 1995-07-25 0 0.99
Paso 4#
Prompt: I want you to act as a python programmer assistant.
Write a code that transform the elements in column “value” of the previous dataframe, when they are of type str. Take into account that the values of type str use “.” to represent thousands and “,” to represent decimals.
Do not explain the code.
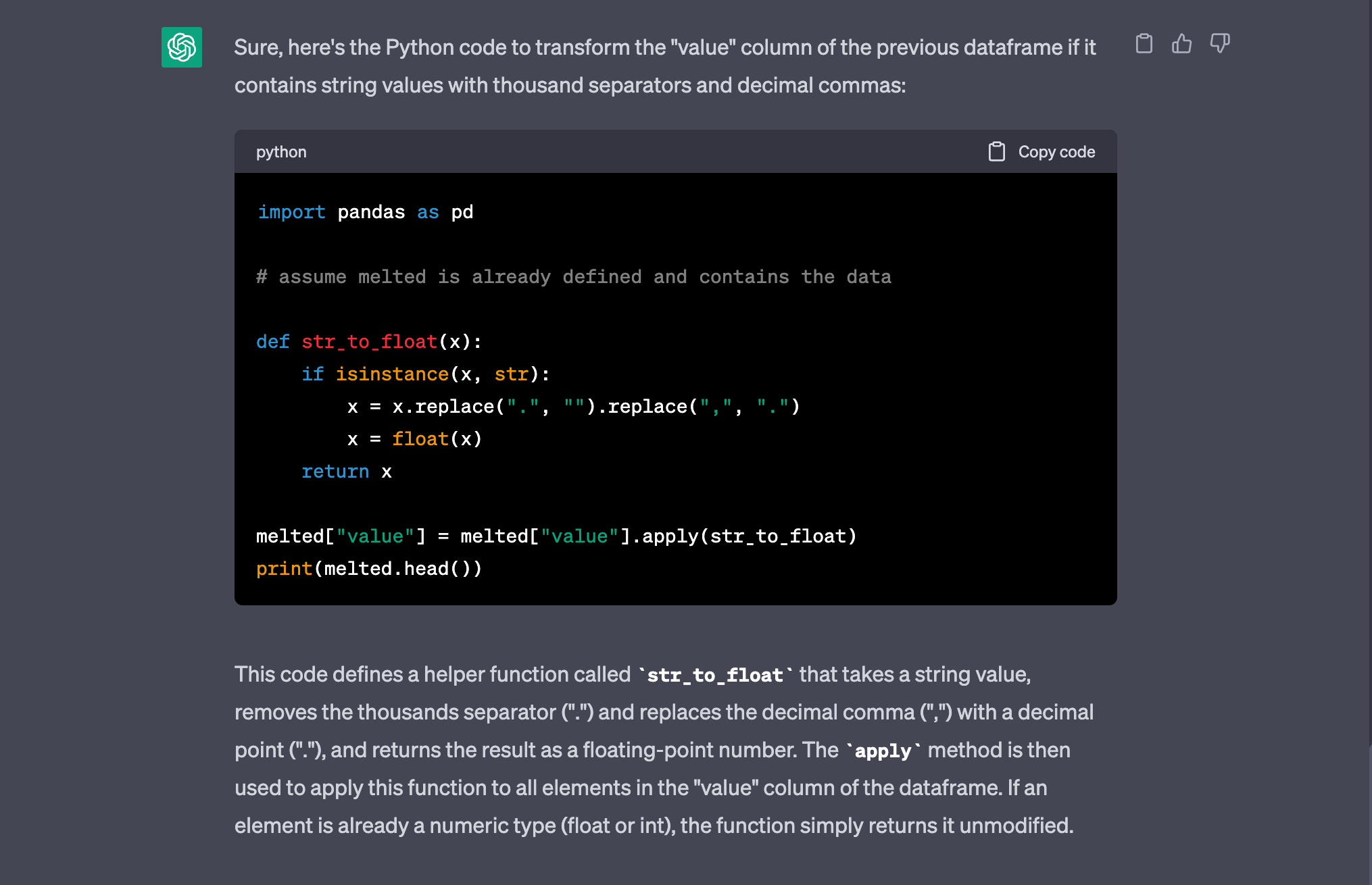
[4]:
def str_to_float(x):
if isinstance(x, str):
x = x.replace(".", "").replace(",", ".")
x = float(x)
return x
melted["value"] = melted["value"].apply(str_to_float)
print(melted.head())
Fecha hour value
0 1995-07-21 0 1.073
1 1995-07-22 0 1.073
2 1995-07-23 0 1.073
3 1995-07-24 0 1.000
4 1995-07-25 0 0.990
Paso 5#
Prompt: I want you to act as a python programmer assistant.
Remove NA values from previous dataframe.
Do not explain the code.
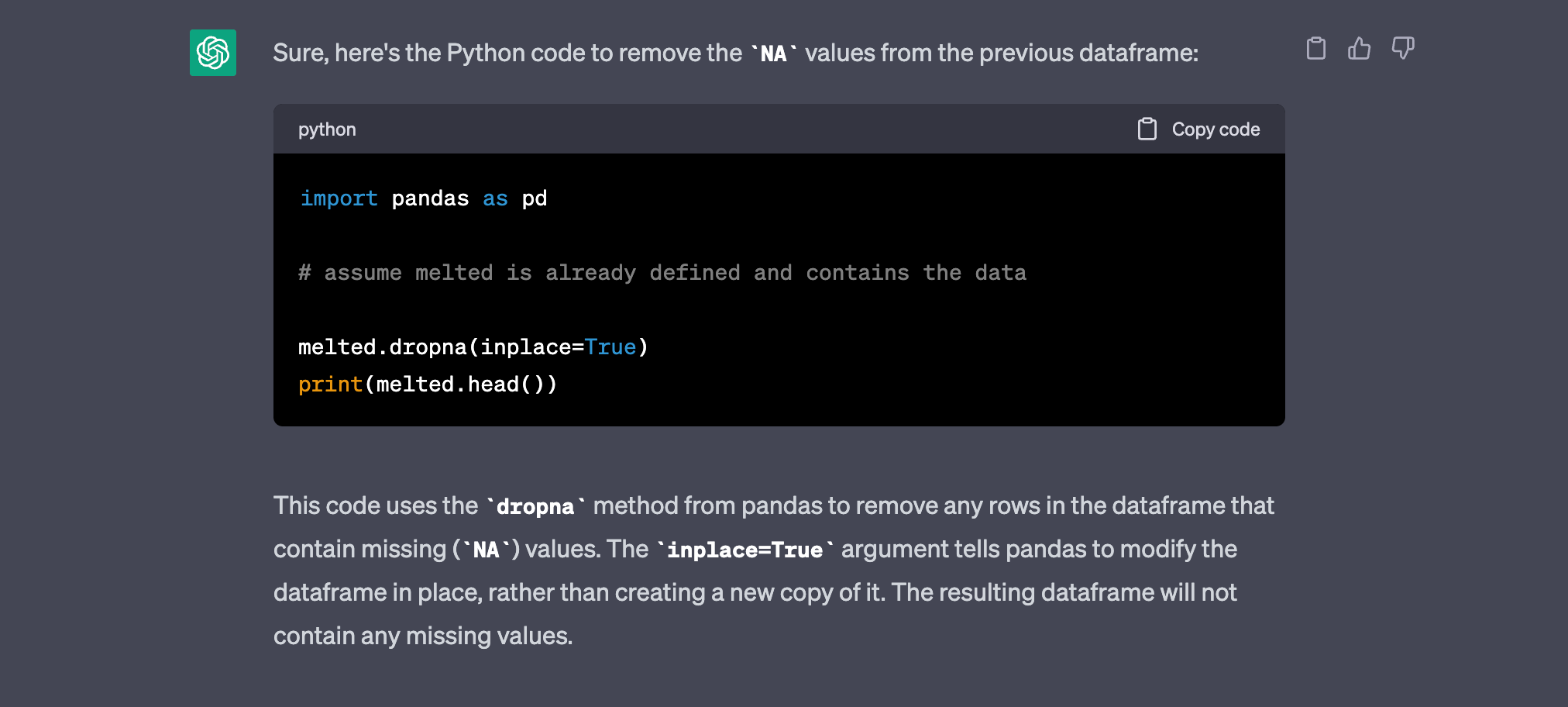
[5]:
melted.dropna(inplace=True)
print(melted.head())
Fecha hour value
0 1995-07-21 0 1.073
1 1995-07-22 0 1.073
2 1995-07-23 0 1.073
3 1995-07-24 0 1.000
4 1995-07-25 0 0.990
Paso 6#
Prompt: I want you to act as a python programmer assistant.
Create a dataframe called “precios_diarios” as the mean values of the column “value” of the previous dataframe grouped by “Fecha” column.
Do not explain the code.
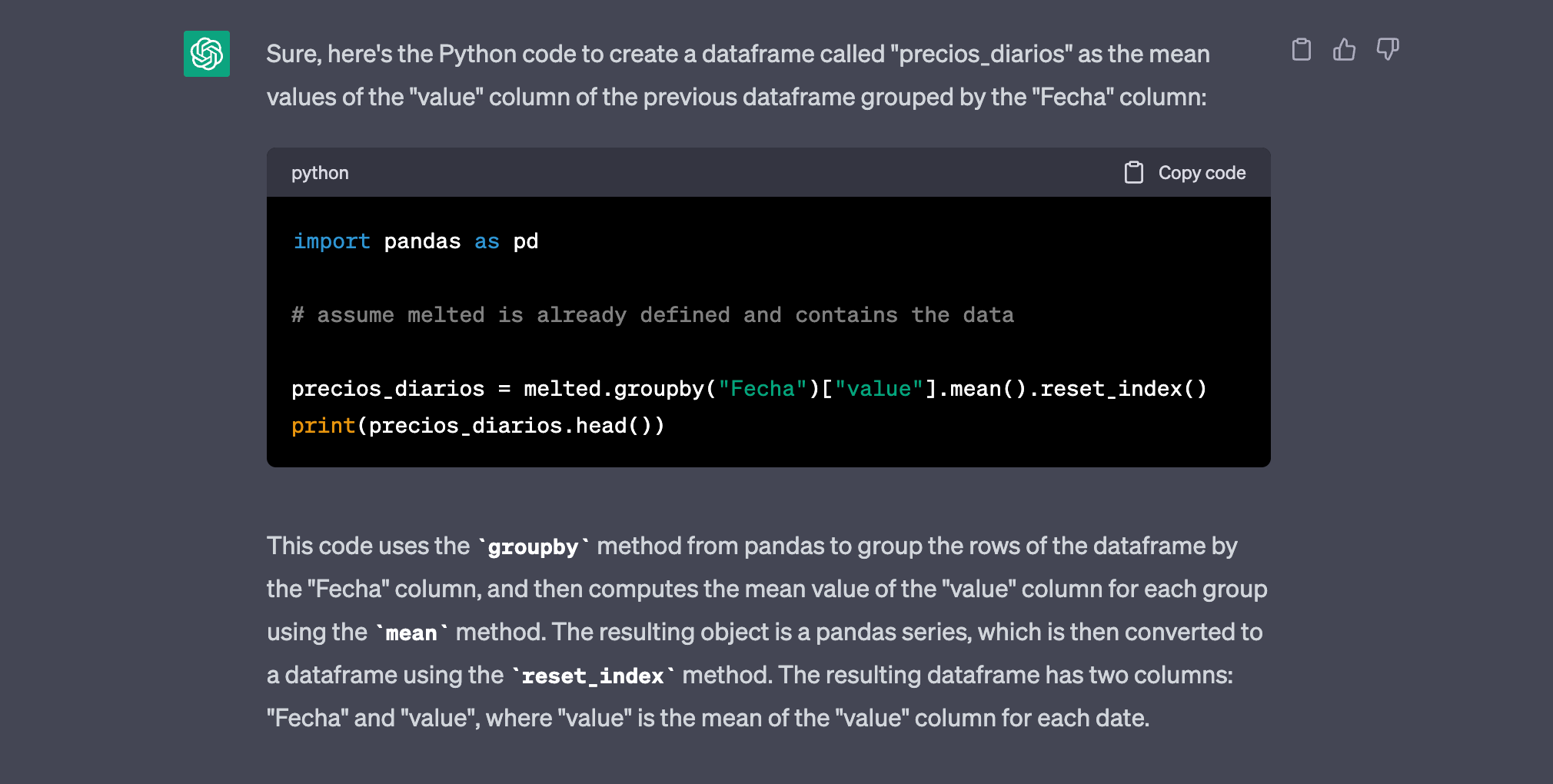
[6]:
precios_diarios = melted.groupby("Fecha")["value"].mean().reset_index()
print(precios_diarios.head())
Fecha value
0 1995-07-21 4.924333
1 1995-07-22 1.269500
2 1995-07-23 0.953083
3 1995-07-24 4.305917
4 1995-07-25 1.149167
Paso 7#
Prompt: I want you to act as a python programmer assistant.
The column “Fecha” of the “melted” dataframe contains dates in the format “YYYY-MM-DD”. Create a dataframe called “precios_mensuales” as the mean values of the column “value” of the “melted” dataframe grouped by year and month, using the transform method. The new dataframe conservs the “Fecha” column.
Do not explain the code.
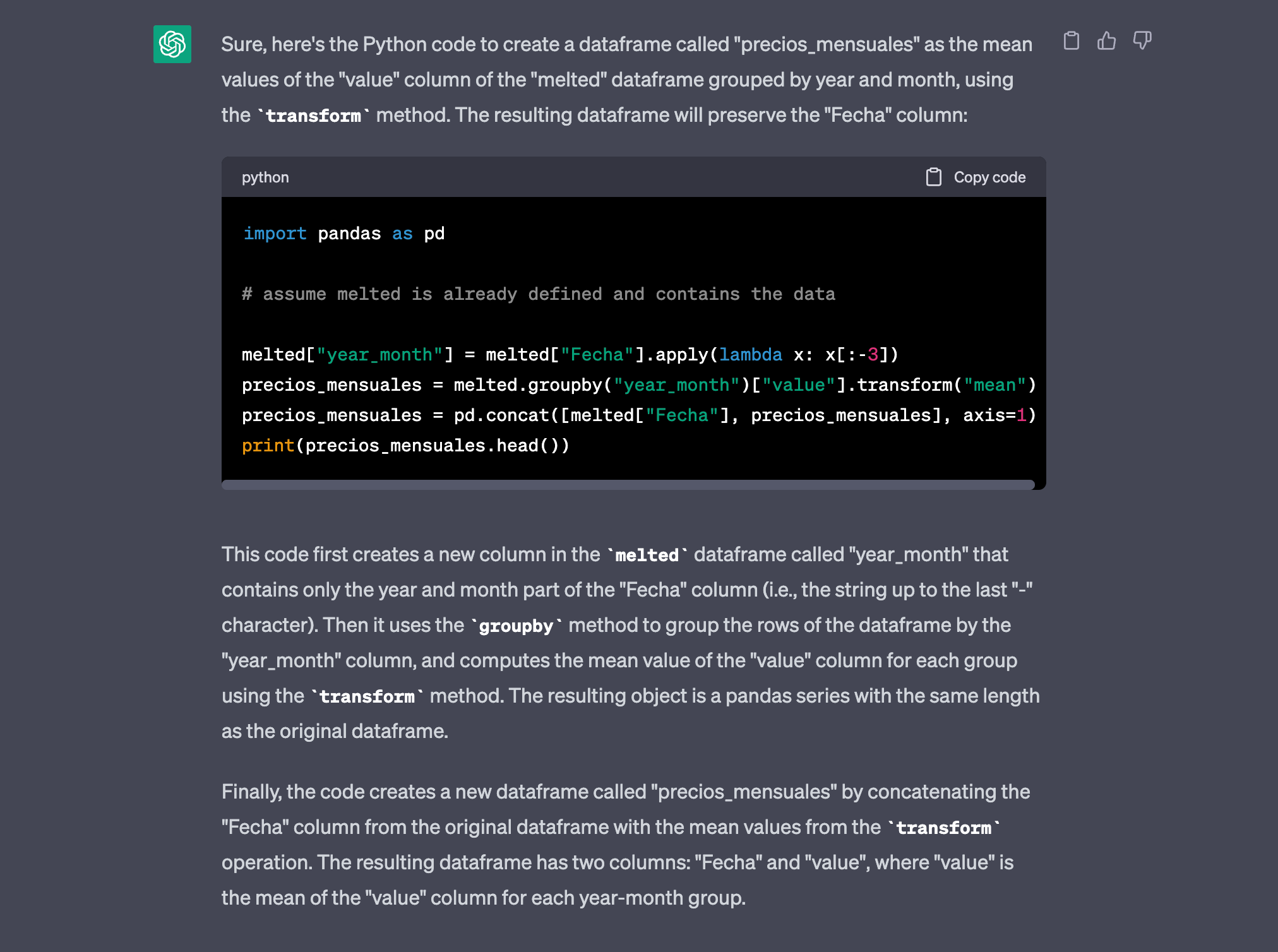
[7]:
melted["year_month"] = melted["Fecha"].apply(lambda x: x[:-3])
precios_mensuales = melted.groupby("year_month")["value"].transform("mean")
precios_mensuales = pd.concat([melted["Fecha"], precios_mensuales], axis=1)
print(precios_mensuales.head())
Fecha value
0 1995-07-21 1.552087
1 1995-07-22 1.552087
2 1995-07-23 1.552087
3 1995-07-24 1.552087
4 1995-07-25 1.552087
Paso 8#
Prompt: I want you to act as a python programmer assistant.
Rename the column “value” in “precios_diarios” dataframe as “precio diario”. Rename the column “value” in “precios_mensuales” dataframe as “precio mensual”.
Do not explain the code.
[8]:
precios_diarios = precios_diarios.rename(columns={"value": "precio diario"})
precios_mensuales = precios_mensuales.rename(columns={"value": "precio mensual"})
print(precios_diarios.head())
print(precios_mensuales.head())
Fecha precio diario
0 1995-07-21 4.924333
1 1995-07-22 1.269500
2 1995-07-23 0.953083
3 1995-07-24 4.305917
4 1995-07-25 1.149167
Fecha precio mensual
0 1995-07-21 1.552087
1 1995-07-22 1.552087
2 1995-07-23 1.552087
3 1995-07-24 1.552087
4 1995-07-25 1.552087
Paso 9#
Prompt: I want you to act as a python programmer assistant.
Create a time plot using matplotlib with the column “precio diario” of “precios_diarios” dataframe, and the column “precio mensual” of “precios_mensuales” dataframe. FixedFormatter should only used with FixedLocator.
Do not explain the code.
[9]:
import matplotlib.pyplot as plt
precios_diarios["Fecha"] = pd.to_datetime(precios_diarios["Fecha"])
precios_mensuales["Fecha"] = pd.to_datetime(precios_mensuales["Fecha"])
precios_diarios = precios_diarios.set_index("Fecha")
precios_mensuales = precios_mensuales.set_index("Fecha")
fig, ax = plt.subplots(figsize=(10, 4))
ax.plot(precios_diarios["precio diario"], label="Precio diario")
ax.plot(precios_mensuales["precio mensual"], label="Precio mensual")
years = pd.date_range(
start=precios_diarios.index.min(), end=precios_diarios.index.max(), freq="YS"
)
ax.set_xticks(years)
ax.set_xticklabels(years.strftime("%Y"), rotation=45, ha="right")
ax.set_ylabel("Precio ($/kWh)")
ax.legend()
plt.show()
