Receiver operating characteristic#
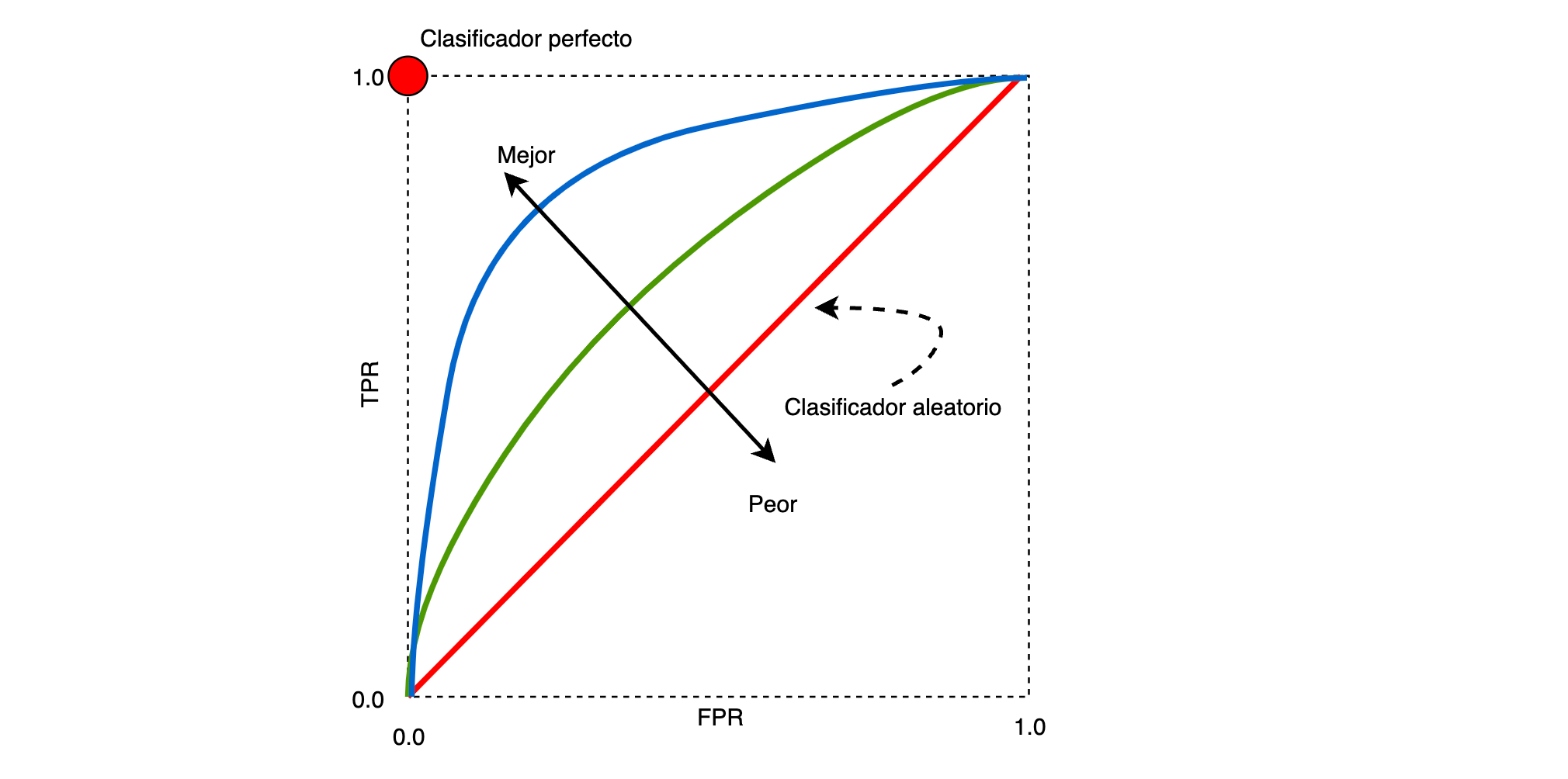
Es una gráfica que compara el desempeño de un clasificador binario cuando se varia la frontera de decisión. La curva se construye al graficar la tasa de verdaderos positivos (TPR, sensibilidad o recall), en el eje Y, vs la tasa de falsos positivos (FPR), en el eje X, al variar la frontera de decisión del clasificador.
Es decir, se expresa la TPR como una función de la FPR.
A partir de la siguiente matriz de confusión:
| Pronostico
| N P
---------|------------
N | TN FP
Real |
P | FN TP
TP - Verdadero positivo (correcto)
TN - Verdadero negativo (correcto)
FN - Falso negativo (mal clasificado)
FP - Falso positivo (mal clasificado)
los valores a graficar se obtienen como:
\text{TPR} = \frac{\text{TP}}{\text{TP}+\text{FP}}
\text{FPR} = \frac{\text{FP}}{\text{FP}+\text{TN}}
La FPR representa la tasa de falsa alarma, esto es: la cantidad de Falsos Positivos sobre la totalidad de negativos.
La TPR es la tasa de casos declarados como positivos, que verdaderamente presetan la condición.
De la gráfica, usualmente se computa el área bajo la curva. A mayor área, es mejor el clasificador.
[1]:
from itertools import cycle
import matplotlib.pyplot as plt
import numpy as np
from scipy import interp
from sklearn import datasets, svm
from sklearn.metrics import auc, roc_auc_score, roc_curve
from sklearn.model_selection import train_test_split
from sklearn.multiclass import OneVsRestClassifier
from sklearn.preprocessing import label_binarize
[2]:
#
# Carga del dataset de datos
#
iris = datasets.load_iris()
X = iris.data
y = iris.target
y
[2]:
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
[3]:
#
# Se binariza la salida para generar tres columnas. La implementación
# está restringida al caso binario.
#
y = label_binarize(y, classes=[0, 1, 2])
n_classes = y.shape[1]
y[:5, :]
[3]:
array([[1, 0, 0],
[1, 0, 0],
[1, 0, 0],
[1, 0, 0],
[1, 0, 0]])
[4]:
#
# Adiciona nuevas variables aleatorias
#
random_state = np.random.RandomState(0)
n_samples, n_features = X.shape
X = np.c_[X, random_state.randn(n_samples, 200 * n_features)]
[5]:
#
# Conjuntos de entrenamiento y validación
#
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.5,
random_state=0,
)
y_train[:10, :]
[5]:
array([[1, 0, 0],
[0, 0, 1],
[0, 1, 0],
[1, 0, 0],
[0, 1, 0],
[0, 0, 1],
[0, 1, 0],
[1, 0, 0],
[0, 0, 1],
[0, 0, 1]])
[6]:
#
# Construye el clasificador que usa la estrategia OneVsRest
#
classifier = OneVsRestClassifier(
svm.SVC(
kernel="linear",
probability=True,
random_state=random_state,
)
)
#
# decision_function: Return the distance of each sample from the decision
# boundary for each class.
#
y_score = classifier.fit(X_train, y_train).decision_function(X_test)
#
# Cálculo de la curva RO
#
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
# -------------------------------------------------------------------------
# fpr: Increasing false positive rates such that element i is the false
# positive rate of predictions with score >= thresholds[i].
# tpr: Increasing true positive rates such that element i is the true
# positive rate of predictions with score >= thresholds[i].
# thresholds: Decreasing thresholds on the decision function used to
# compute fpr and tpr.
fpr[i], tpr[i], _ = roc_curve(
# ---------------------------------------------------------------------
# True binary labels, {-1, 1} or {0, 1}
y_true=y_test[:, i],
# ---------------------------------------------------------------------
# Target scores, can either be probability estimates of the positive
# class, confidence values, or non-thresholded measure of decisions (as
# returned by “decision_function” on some classifiers).
y_score=y_score[:, i],
)
# -------------------------------------------------------------------------
# Compute Area Under the Curve (AUC) using the trapezoidal rule.
roc_auc[i] = auc(
x=fpr[i],
y=tpr[i],
)
[7]:
#
# False positive rate
#
fpr
[7]:
{0: array([0. , 0. , 0. , 0.01851852, 0.01851852,
0.03703704, 0.03703704, 0.05555556, 0.05555556, 0.07407407,
0.07407407, 0.09259259, 0.09259259, 0.12962963, 0.12962963,
0.14814815, 0.14814815, 0.2037037 , 0.2037037 , 0.27777778,
0.27777778, 1. ]),
1: array([0. , 0. , 0. , 0.02222222, 0.02222222,
0.11111111, 0.11111111, 0.17777778, 0.17777778, 0.2 ,
0.2 , 0.24444444, 0.24444444, 0.26666667, 0.26666667,
0.37777778, 0.37777778, 0.42222222, 0.42222222, 0.48888889,
0.48888889, 0.55555556, 0.55555556, 0.62222222, 0.62222222,
0.64444444, 0.64444444, 0.66666667, 0.66666667, 0.73333333,
0.73333333, 0.75555556, 0.75555556, 0.88888889, 0.88888889,
1. ]),
2: array([0. , 0. , 0. , 0.01960784, 0.01960784,
0.07843137, 0.07843137, 0.09803922, 0.09803922, 0.11764706,
0.11764706, 0.1372549 , 0.1372549 , 0.15686275, 0.15686275,
0.17647059, 0.17647059, 0.31372549, 0.31372549, 0.33333333,
0.33333333, 0.35294118, 0.35294118, 0.41176471, 0.41176471,
0.45098039, 0.45098039, 0.47058824, 0.47058824, 0.50980392,
0.50980392, 0.56862745, 0.56862745, 1. ])}
[8]:
#
# True positive rate
#
tpr
[8]:
{0: array([0. , 0.04761905, 0.14285714, 0.14285714, 0.19047619,
0.19047619, 0.33333333, 0.33333333, 0.38095238, 0.38095238,
0.61904762, 0.61904762, 0.66666667, 0.66666667, 0.76190476,
0.76190476, 0.9047619 , 0.9047619 , 0.95238095, 0.95238095,
1. , 1. ]),
1: array([0. , 0.03333333, 0.13333333, 0.13333333, 0.16666667,
0.16666667, 0.2 , 0.2 , 0.26666667, 0.26666667,
0.33333333, 0.33333333, 0.4 , 0.4 , 0.43333333,
0.43333333, 0.5 , 0.5 , 0.56666667, 0.56666667,
0.6 , 0.6 , 0.63333333, 0.63333333, 0.7 ,
0.7 , 0.73333333, 0.73333333, 0.9 , 0.9 ,
0.93333333, 0.93333333, 0.96666667, 0.96666667, 1. ,
1. ]),
2: array([0. , 0.04166667, 0.125 , 0.125 , 0.25 ,
0.25 , 0.29166667, 0.29166667, 0.33333333, 0.33333333,
0.41666667, 0.41666667, 0.5 , 0.5 , 0.54166667,
0.54166667, 0.58333333, 0.58333333, 0.70833333, 0.70833333,
0.75 , 0.75 , 0.79166667, 0.79166667, 0.83333333,
0.83333333, 0.875 , 0.875 , 0.91666667, 0.91666667,
0.95833333, 0.95833333, 1. , 1. ])}
[9]:
roc_auc
[9]:
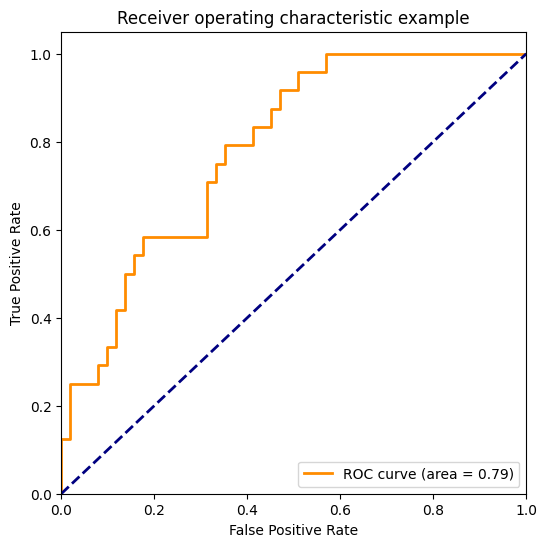
{0: 0.9126984126984127, 1: 0.6037037037037037, 2: 0.7867647058823529}
[10]:
plt.figure(figsize=(6, 6))
plt.plot(
fpr[2],
tpr[2],
color="darkorange",
lw=2,
label="ROC curve (area = %0.2f)" % roc_auc[2],
)
plt.plot([0, 1], [0, 1], color="navy", lw=2, linestyle="--")
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("Receiver operating characteristic example")
plt.legend(loc="lower right")
plt.show()