Definición#
Ultima modificación: 2023-03-11 | YouTube
Es un metodo de aprendizaje supervisado no paramétrico usado para clasificación y regresión.
El modelo aprende reglas de decisión simples que pueden ser inferidas de los datos.
Scikit-learn implementa el algoritmo CART.
Su estructura puede interpretarse como un árbol de decisiones, el cual parte del dominio de las variables independienes en regiones. Para decidir que región asignar a un nuevo punto (x_1, x_2) simplemente se recorre el árbol de decisión usando los valores x_1 y x_2.
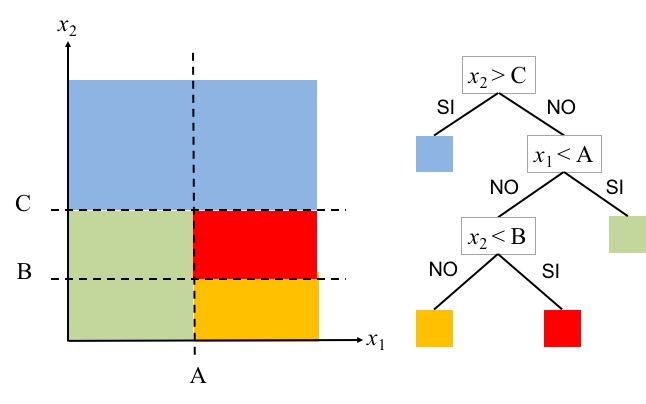
El árbol de la derecha puede interpretarse como un conjunto de reglas if anidadas:
if x2 > C then class = azul else if x1 < A then class = verde else if x2 < B then class = rojo else class = amarillo end if end if end if
Sus ventajas son las siguientes:
Es fácil de entender e interpretar, y puede ser visualizado.
Requere poca preparación de la data. No requiere normalización ni creación de variables dummy.
Es computacionalmente eficiente en pronóstico.
Se considera un modelo de caja blanca, es decir, es facil explicar un resultado entregado por el modelo.
Es posible validar el modelo usando técnicas estadísticas.
Tiene un buen comportamiento aunque se violen los supuestos de los datos que fueron usados para entrenar el modelo.
Su desventajas son las siguientes:
Pueden presentar sobreajuste.
Pueden ser inestables, es decir, pequeñas variaciones en los datos pueden producir árboles completamente diferentes.
La predicción es brusca y discontinua, similar a los modelos lineales por tramos.
No son buenos modelos para extrapolar.
La obtención de un árbol de decisión óptimo es tipo NP-completo, por lo que se usan algoritmos heurísticos.
Existen conceptos que un árbol no puede expresar fáciltmente como los problemas XOR, paridad o multiplexers.
Para su uso práctico se deben tener en cuenta los siguientes puntos:
Los árboles decisión tienden a sobreajustar datasets con un número grande de características.
Se recomienda utilizar técnicas de reducción de la dimensinalidad (PCA, ICA, selección de características) antes de entrenar el árbol.
Se debe analizar la estructura del árbol de decisión y visualizarla.
Se debe controlar la profundidad del árbol para prevenir sobreajuste.
Se debe controlar el número mínimo de patrones asociados a un nodo.
En clasificación el dataset debería ser balanceado para evitar que el árbol se sesge hacia la clase más frecuente.
En lo posible se deben usar pesos para los patrones o ejemplos, con el fin de facilitar la optimización del árbol.