Vecinos próximos para clasificación — 10:36 min#
10:36 min | Ultima modificación: Septiembre 24, 2021 | YouTube
El problema de clasificación en términos matemáticos se define de la siguiente forma.
Se tienen M ejemplos.
Cada ejemplo esta definido por un conjunto de variables (x_1, x_2, …, x_N).
Cada ejemplo pertenece a una clase y hay P clases diferentes.
Para un nuevo caso no clasificado y con base en los M ejemplos disponibles, se desea pronosticar a que clase pertenece este.
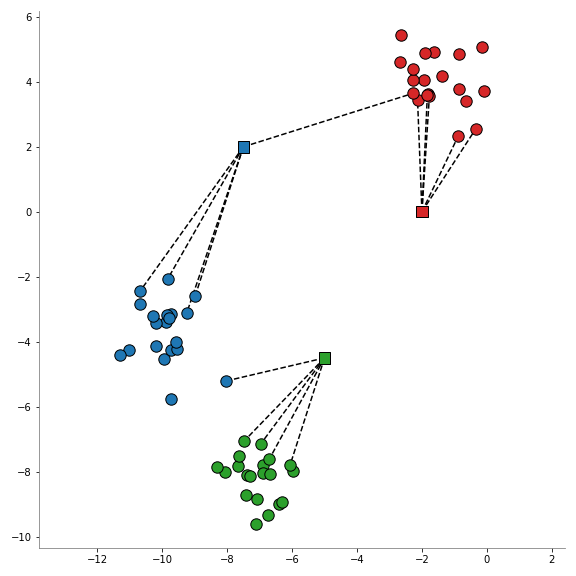
El método k-NN asigna una clase (de las P posibles) al nuevo ejemplo en dos pasos. En el primer paso, determina los k ejemplos más cercanos (distancia) al nuevo ejemplo; en el segundo paso, asigna la clase al nuevo punto por mayoría; es decir, asigna la clase con mayor frecuencia entre los k vecinos más cercanos. Por ejemplo, si se consideran 7 vecinos, de los cuales 5 pertenecen a P_1 y 2 pertencen a P_2 entonces el nuevo punto es clasificado como P_1.
La lógica de este método se basa en el siguiente razonamiento: Si un nuevo patrón (ejemplo) es más cercano en distancia a los ejemplos de la clase azul que a los ejemplos del resto de clases, entonces pertenece a la clase A.
Métricas de distancia#
Existen distintas métricas para computar la distancia entre puntos.
Ver:
https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.DistanceMetric.html
Dataset#
[1]:
import numpy as np
from sklearn.datasets import make_blobs
#
# Dataset
#
NPOINTS = 60
X, y = make_blobs(
n_samples=NPOINTS,
n_features=2,
centers=3,
cluster_std=0.9,
shuffle=False,
random_state=1,
)
X_new = np.array(
[
[-7.5, 2],
[-5, -4.5],
[-2, 0],
]
)
K-Neighbors Classifier#
[2]:
from sklearn.neighbors import KNeighborsClassifier
kneighborsClassifier = KNeighborsClassifier(
# -----------------------------------------------------
# Number of neighbors to use by default for kneighbors
# queries.
n_neighbors=5,
# -----------------------------------------------------
# 'auto', 'ball_tree', 'kd_tree', 'brute'
algorithm="auto",
)
kneighborsClassifier.fit(X, y)
kneighborsClassifier.predict(X_new)
[2]:
array([1, 2, 0])
Radius Neighbors Classifier#
[3]:
from sklearn.neighbors import RadiusNeighborsClassifier
radiusNeighborsClassifier = RadiusNeighborsClassifier(
# -----------------------------------------------------
# Range of parameter space to use by default for
# radius_neighbors queries.
radius=5,
# -----------------------------------------------------
# 'auto', 'ball_tree', 'kd_tree', 'brute'
algorithm="auto",
)
radiusNeighborsClassifier.fit(X, y)
radiusNeighborsClassifier.predict(X_new)
[3]:
array([1, 2, 0])
Nearest Centroid Classifier#
[4]:
from sklearn.neighbors import NearestCentroid
nearestCentroid = NearestCentroid()
nearestCentroid.fit(X, y)
nearestCentroid.predict(X_new)
[4]:
array([1, 2, 0])
[5]:
def fig_nearest_neightbors_classifier():
import matplotlib.pyplot as plt
from sklearn.neighbors import NearestNeighbors
plt.figure(figsize=(8, 8))
plt.scatter(X[:20, 0], X[:20, 1], s=130, color="tab:red", edgecolors="k")
plt.scatter(X[20:40, 0], X[20:40, 1], s=130, color="tab:blue", edgecolors="k")
plt.scatter(X[40:, 0], X[40:, 1], s=130, color="tab:green", edgecolors="k")
plt.axis("equal")
#
# Puntos de prueba
#
colors = ["tab:blue", "tab:green", "tab:red"]
plt.scatter(
X_new[:, 0],
X_new[:, 1],
marker="s",
s=130,
edgecolors="black",
c=colors,
zorder=10,
)
nearestNeighbors = NearestNeighbors(
n_neighbors=5,
algorithm="kd_tree",
).fit(X)
neighbors = nearestNeighbors.kneighbors(X_new, 5, return_distance=False)
for i_new_point in range(len(X_new)):
for neighbor in neighbors[i_new_point]:
plt.plot(
[X_new[i_new_point][0], X[neighbor, 0]],
[X_new[i_new_point][1], X[neighbor, 1]],
"--k",
zorder=0,
)
plt.gca().spines["left"].set_color("gray")
plt.gca().spines["bottom"].set_color("gray")
plt.gca().spines["top"].set_visible(False)
plt.gca().spines["right"].set_visible(False)
plt.tight_layout()
plt.savefig("assets/nearestNeighborsClassifier.png")
plt.close()
# fig_nearest_neightbors_classifier()