La función make_classification — 5:02 min#
5:02 min | Ultima modificación: Septiembre 27, 2021 | YouTube
Generación aleatoria de un problema de clasificación de n clases.
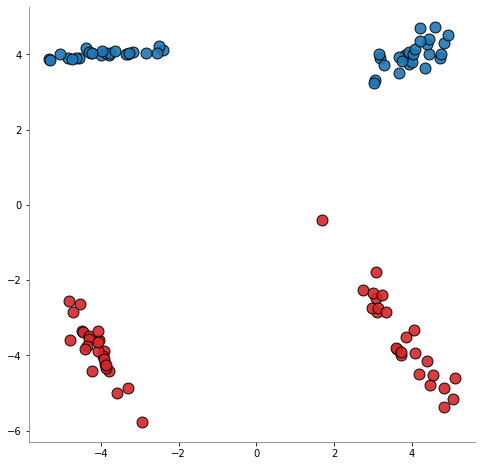
[1]:
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
X, y = make_classification(
# -------------------------------------------------------------------------
# The number of samples.
n_samples=100,
# -------------------------------------------------------------------------
# The total number of features. These comprise n_informative informative
# features, n_redundant redundant features, n_repeated duplicated features
# and n_features-n_informative-n_redundant-n_repeated useless features
# drawn at random.
n_features=2,
# -------------------------------------------------------------------------
# The number of informative features.
n_informative=2,
# -------------------------------------------------------------------------
# The number of redundant features.
n_redundant=0,
# -------------------------------------------------------------------------
# The number of duplicated features, drawn randomly from the informative
# and the redundant features.
n_repeated=0,
# -------------------------------------------------------------------------
# The number of classes (or labels) of the classification problem
n_classes=2,
# -------------------------------------------------------------------------
# The number of clusters per class.
n_clusters_per_class=1,
# -------------------------------------------------------------------------
# The factor multiplying the hypercube size. Larger values spread out the
# clusters/classes and make the classification task easier.
class_sep=1.5,
# -------------------------------------------------------------------------
# Shuffle the samples.
shuffle=False,
# -------------------------------------------------------------------------
# Determines random number generation for dataset creation.
random_state=12346,
)
plt.figure(figsize=(8, 8))
plt.scatter(
X[y == 0, 0],
X[y == 0, 1],
color="tab:red",
edgecolors="k",
s=120,
alpha=0.9,
)
plt.scatter(
X[y == 1, 0],
X[y == 1, 1],
color="tab:blue",
edgecolors="k",
s=120,
alpha=0.9,
)
plt.gca().spines["left"].set_color("gray")
plt.gca().spines["bottom"].set_color("gray")
plt.gca().spines["top"].set_visible(False)
plt.gca().spines["right"].set_visible(False)
plt.show()
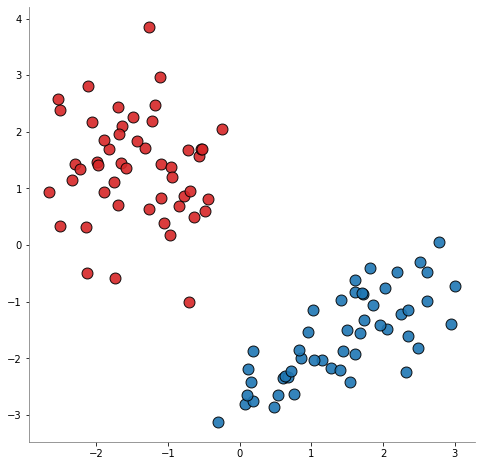
[2]:
X, y = make_classification(
n_samples=100,
n_features=2,
n_informative=2,
n_redundant=0,
n_repeated=0,
n_classes=2,
n_clusters_per_class=2,
class_sep=4.0,
shuffle=False,
random_state=12346,
)
plt.figure(figsize=(8, 8))
plt.scatter(
X[y == 0, 0],
X[y == 0, 1],
color="tab:red",
edgecolors="k",
s=120,
alpha=0.9,
)
plt.scatter(
X[y == 1, 0],
X[y == 1, 1],
color="tab:blue",
edgecolors="k",
s=120,
alpha=0.9,
)
plt.gca().spines["left"].set_color("gray")
plt.gca().spines["bottom"].set_color("gray")
plt.gca().spines["top"].set_visible(False)
plt.gca().spines["right"].set_visible(False)
plt.show()